

When contemplating a new venture into AI or machine learning, companies need to take on a number of important considerations that relate to talent, existing data, and limitations. One way executives can judge how successful or appropriate and AI project would be for their company is to examine use cases of businesses that have previously done something similar.
With AI and machine learning news increasing in tech media, a business leader may find it challenging to cut through the hype and identify valid, useful case studies.
We talked to Ben Lorica, PhD, Chief Data Scientist at O’Reilly Media, to get his insights on what key details executives should be looking for within a case study.
Subscribe to our AI in Industry Podcast with your favorite podcast service:




While a business leader does not need to become a technical expert in AI to understand case studies, Lorica says that it’s important for them to understand the basics of AI and what it takes to implement it.
“People focus a lot on the model, but when you get into the details, it’s about more than just building a cool model,” Lorica says.
“At a high-level people understand the basics of these technologies,” he adds. “So AI and analytics are often used to improve decision-making or automation.”
In many use cases, Lorica says teams which create a successful AI model often take the following steps:
- Determine where data will come from, and how it will be collected if it has not been
- Find the right talent for each job, which could include data collection or maintaining algorithms when necessary.
- Enable some type of automation to improve decision making.
- Take a step back and understand key technology and limitations.
Adding Deep Learning to a Scalable Model
When discussing the example of creating an AI algorithm to organize and rout customer support tickets to the right staff member, Lorica noted important steps to take for a smooth implementation process, as well as what questions a business leader may answer with a case study:
“When routing support tickets, we want to be able to get those to the right people. It would be worth looking at:
- What are the current natural language processing (NLP) approaches?
- What are strengths and weaknesses of the technology firm?
- What kind of data was needed?
- Where was it taken from?
“In that specific example…the data is already available — but right now, a lot of the routing and a lot of the work is being done manually …You might already have an initial corpus of data, and more importantly, that data has been routed properly by a human domain expert. You have the basic ingredients of automating that task”
Lorica says that while routing is a good example of something that could smoothly be automated through an AI project, an executive should still use case studies to learn how and if it could be successfully scaled.
“Once you determine that you have the scale, you have to determine the data in order to go forward with this automation project.” he says.
The Growing Talent Gap
When looking at case studies, Lorica says it is important to note what type of talent a company used, and whether talent was sourced in-house, from an outside vendor, or from a combination of both internal and external areas. With continuous research showing that there is a growing talent gap in the areas of AI and machine learning, a business leader may want to use case studies to see how companies assigned or trained team members to handle an AI project, or how they scouted an ML or AI expert.
The chart below, from O’Railly’s recent study, shows how most participants said that their number one bottleneck was a growing talent gap

For example, if data has not been collected or cleaned, a company may need a team of data scientists or data engineers to find and organize it in preparation for an AI project. From there, these data scientists, machine learning or AI experts could be involved with building and training the algorithm.
“At this stage in the revolution of these technologies, you have access to cloud computing services so you can go that rout if your comfortable using managed services — Which means you might need to have less people to maintain infrastructure particularly on these open source projects. … You could conceivably use machine learning services in the cloud. Then you’ll also need less people to maintain those machine learning libraries in house. “
In an interview with Hired.com’s Data Science Leader, Parshu Kulkarni, he explained how he selects the right candidate to fill a position in the machine learning field.
“One of the things that I look for in a data scientist is experience dealing with problems, not just the ability to explain algorithms, but have they demonstrated instances where they have previously used some of these ML and applications?” Kulkarni said.
“Say somebody worked at a search engine company like Google, they might have worked on using ML algorithms for certain applications to improve search elements.” he continued.
“One of the things I tend to look for is instances where the candidate has been able to apply algorithms to solve a critical business problem that resulted in a positive business outcome. … Not only do they have the technical skills, but they have the business sense to identify the opportunities where the solutions can be applied.”
Lorica similarly noted that successful companies also use a combination of data scientists and data engineers even after an AI program or platform is implemented.
The figure below notes the key tasks of data scientists versus data engineers, as well as where they might overlap.
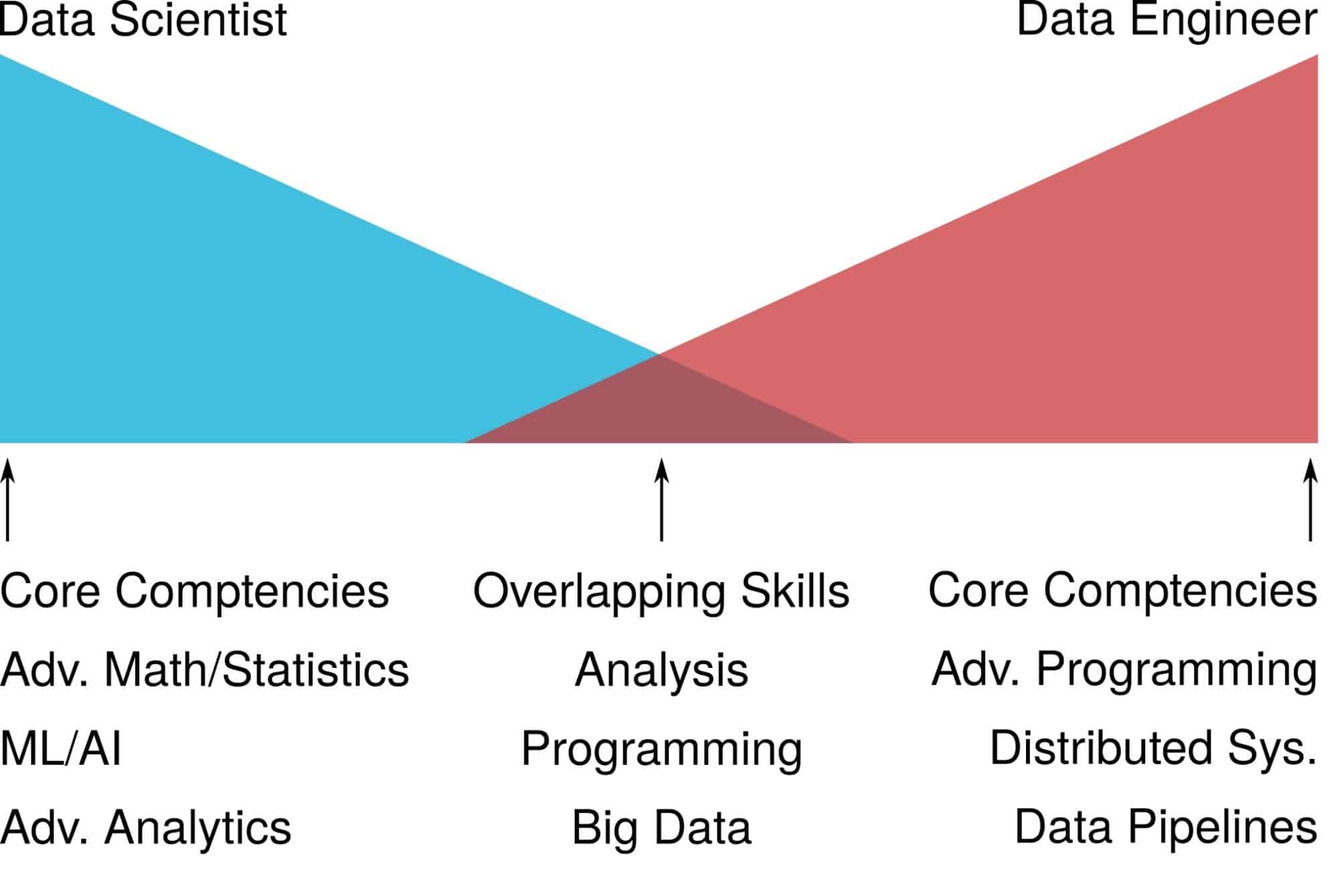
“You probably will still need people to make sure data pipelines are flowing and models are working,” Lorica says.
“There’s this notion of concept drift. Your model gets stale and [algorithms] need to be retrained. You need someone to recognize that or set up alerts for an automated way of learning. A combination of data engineers and data scientists are what I want to have access to.”
Lorica continued, “You can feed data into a library and get a result but You still need experience and training to interpret those results.”
Data Collection and Maintenance
“If you don’t have historical data, you must come up with a process to start labeling and storing data that may be able to help you scale,” Lorica says.
As Lorica notes, a strong use case will discuss where and how a company gets data needed to feed its algorithm. The use case will also note how it continued to keep its data streams in check, whether it involves the algorithm, or human scientists to continue feeding and training a software.
In our recent report on predictive analytics in finance, we highlighted a use case from Danske Bank, which used an AI technology called Teradata to improve their fraud prediction models.
The study noted that while a banker or employee could use the platform after it was implemented, preparing the application required a foundation of hand-in-hand work between Teradata data scientists and a team within the bank. This implementation involved finding and cleaning relevant bank data which they would need for the Teradata’s predictive analytics algorithm to detect and alert a banking team of a potentially fraudulent chronological path of banking actions.
By acknowledging that outside data scientists and various types of internal experts needed to work together, Dankse Bank’s study hints to the detail in steps needed to make the service accessible for all bank employees or financial analysts.
When it comes to stories of data management, a strong use case also could acknowledge how a company handled or considered various risks.
“I’ve been starting to collect these challenges under the umbrella of risk,” Lorica says. “Once you start using and deploying machine learning models they may go bad — or start exhibiting bias and strange behavior.”
An example that Lorica gave of bad model behavior could be leaking private data.
“A lot of privacy challenges are internal,” he explains. “They’re from people having access that they shouldn’t have. People at Lyft had access to data and were looking into the data of their friends. Machine learning data on mobile phones can be leaked.”
He also adds that there could be adversarial risk, where a competitor may figure out how to hack another company’s machine learning platform and train it to misbehave or leak information. In one example, to explore the possibilities of adversarial hacking, researchers at Massachusetts Institute of Technology recently retrained an algorithm to misidentify a 3D-printed turtle as other objects including a rifle. They also trained it to recognize a baseball as an espresso coffee, according to the study.
“We default to some of the more recent examples in media, but click fraud or flooding product reviews with fake reviews also count,” Lorica explained.
To combat this, companies may continue to use human analysts and data scientists to train ML to help identify attacks. In 2017, researchers at MIT’s Computer Science and Artificial Laboratory (CSAIL) teamed up with startup PatternEx to launch a cybersecurity system which would identify algorithmic signs of attack and send necessary information to an analyst who could confirm, combat and correct the attack.
“We are now entering an age where we have to have all these considerations beyond business metrics and machine learning metrics. The machine learning community of researchers are aware of and engaged in this issue. People are trying to develop private machine learning methods,” Lorica says.
The Big Picture
Overall, a strong case study will enable a business leader or decision-maker to look at a project’s detailed end to end process:
“Understand that machine learning is not just a model. It starts from data collection and goes all the way to deploying the model and then to production. [Some must take into account] all the data prep and cleaning you have to do along the way, or data augmentation if you have to add more data.“
Based on the research of O’Reilly, Lorica, and TechEmergence, we’ve provided a few key questions that a strong case study will answer:
- What was the company’s original process before implementing an AI strategy?
- How did they scale this process? Was it scalable?
- Where did the data used to train algorithms come from? Was it ready and organized, or was a collection and cleaning process required?
- What talent was needed (i.e. data scientists or engineers)? And which aspects of the project did they manage?
Along with the above questions, it is also important to focus on case studies which include the following details
- Specific results with numbers preferred over percentages.
- If looking at a press release or case study directly from an AI service or vendor, take note of whether or not its leader has a robust AI background.
- Credible AI companies may be led by those with Masters or higher in computer science, or by someone who once managed AI or machine learning projects at a major company such as Google or IBM.
- Focus on use-cases which include the specifics on cost and time needed to fully implement an AI process.
“There also must be an understanding that there’s a lot of considerations like privacy, security, and end-to-end requirements much more than modeling skills,” Lorica concluded.
Subscribe to our AI in Industry Podcast with your favorite podcast service:
This article was sponsored by O’Reilly Media, and was written, edited and published in alignment with our transparent Emerj sponsored content guidelines. Learn more about reaching our AI-focused executive audience on our Emerj advertising page.
Header image credit: Edgy Labs





