

When it comes to effectiveness of machine learning, more data almost always yields better results—and the healthcare sector is sitting on a data goldmine. McKinsey estimates that big data and machine learning in pharma and medicine could generate a value of up to $100B annually, based on better decision-making, optimized innovation, improved efficiency of research/clinical trials, and new tool creation for physicians, consumers, insurers, and regulators.
Where does all this data come from? If we could look at labeled data streams, we might see research and development (R&D); physicians and clinics; patients; caregivers; etc. The array of (at present) disparate origins is part of the issue in synchronizing this information and using it to improve healthcare infrastructure and treatments. Hence, the present-day core issue at the intersection of machine learning and healthcare: finding ways to effectively collect and use lots of different types of data for better analysis, prevention, and treatment of individuals.
Burgeoning applications of ML in pharma and medicine are glimmers of a potential future in which synchronicity of data, analysis, and innovation are an everyday reality.
At Emerj, the AI Research and Advisory Company, we research how AI is impacting the pharmaceutical industry as part of our AI Opportunity Landscape service. Global pharma companies use AI Opportunity Landscapes to find out where AI fits at their company and which AI applications are driving value in the industry.
In this article, we use insights from our research to provide a breakdown of several of the pioneering applications of AI in pharma and areas for continued innovation.

Applications of Machine Learning in Pharma and Medicine
1 – Disease Identification/Diagnosis
Disease identification and diagnosis of ailments is at the forefront of ML research in medicine. According to a 2015 report issued by Pharmaceutical Research and Manufacturers of America, more than 800 medicines and vaccines to treat cancer were in trial. In an interview with Bloomberg Technology, Knight Institute Researcher Jeff Tyner stated that while this is exciting, it also presents the challenge of finding ways to work with all the resulting data. “That is where the idea of a biologist working with information scientists and computationalists is so important,” said Tyner.
It’s no surprise that large players were some of the first to jump on the bandwagon, particularly in high-need areas like cancer identification and treatment. In October 2016, IBM Watson Health announced IBM Watson Genomics, a partnership initiative with Quest Diagnostics, which aims to make strides in precision medicine by integrating cognitive computing and genomic tumor sequencing.
Boston-based biopharma company Berg is using AI to research and develop diagnostics and therapeutic treatments in multiple areas, including oncology. Current research projects underway include dosage trials for intravenous tumor treatment and detection and management of prostate cancer.
Other major examples include Google’s DeepMind Health, which last year announced multiple UK-based partnerships, including with Moorfields Eye Hospital in London, in which they’re developing technology to address macular degeneration in aging eyes.
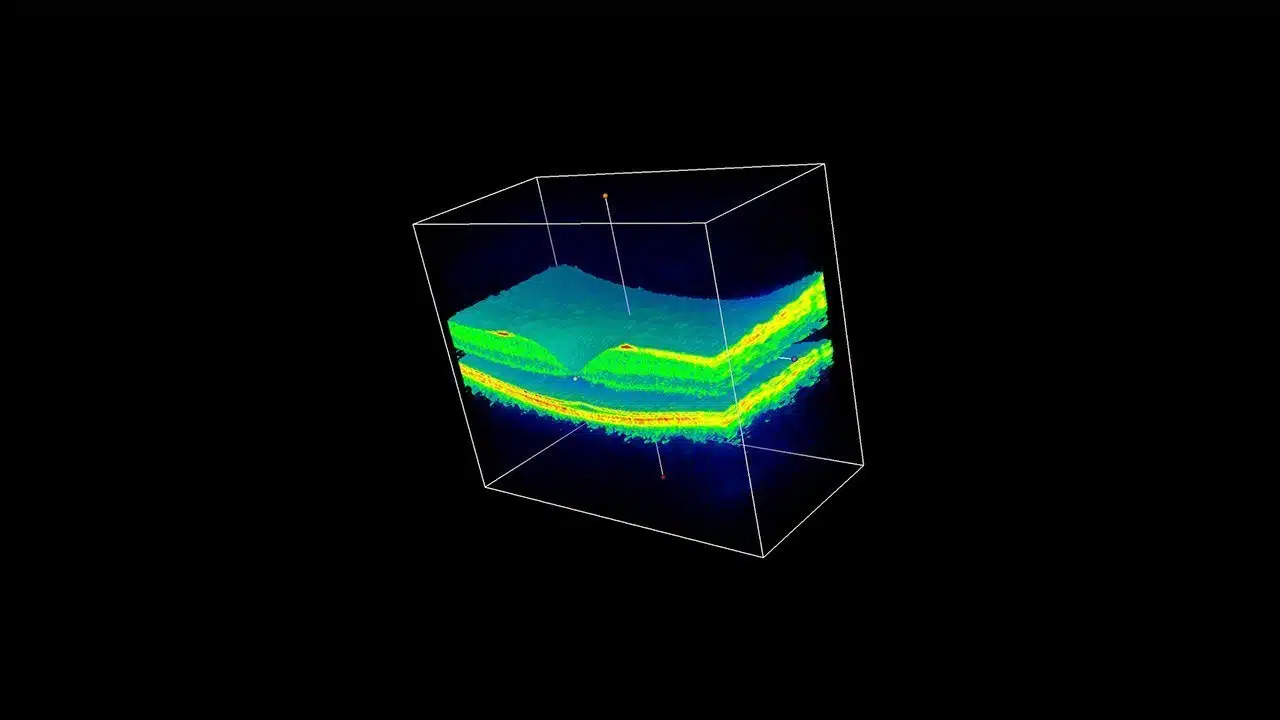
Image credit: Google DeepMind Health – An OCT scan of one of the DeepMind Health team’s eyes
In the area of brain-based diseases like depression, Oxford’s P1vital® Predicting Response to Depression Treatment (PReDicT) project is using predictive analytics to help diagnose and provide treatment, with the overall goal of producing a commercially-available emotional test battery for use in clinical settings.
2 – Personalized Treatment/Behavioral Modification
Personalized medicine, or more effective treatment based on individual health data paired with predictive analytics, is also a hot research area and closely related to better disease assessment. The domain is presently ruled by supervised learning, which allows physicians to select from more limited sets of diagnoses, for example, or estimate patient risk based on symptoms and genetic information.
IBM Watson Oncology is a leading institution at the forefront of driving change in treatment decisions, using patient medical information and history to optimize the selection of treatment options:
IBM Watson and Memorial Sloan Kettering
Over the next decade, increased use of micro biosensors and devices, as well as mobile apps with more sophisticated health-measurement and remote monitoring capabilities, will provide another deluge of data that can be used to help facilitate R&D and treatment efficacy. This type of personalized treatment has important implications for the individual in terms of health optimization, but also for reducing overall healthcare costs. If more patients adhere to following prescribed medicine or treatment plans, for example, the decrease in health-care costs will trickle up and (hopefully) back down.
Behavioral modification is also an imperative cog in the prevention machine, a notion that Catalia Health’s Cory Kidd talked about in a December interview with Emerj. And there are plenty of start-ups popping up in the cancer identification, prevention, and treatment space (for example), with varying degrees of success. A select two from a round-up in Entrepeneur include:
- Somatix – a data-analytics B2B2C software platform company whose ML-based app uses “recognition of hand-to-mouth gestures in order to help people better understand their behavior and make life-affirming changes”, specifically in smoking cessation.
- SkinVision – the self-described “skin cancer risk app” makes its claim as “the first and only CE certified online assessment.” Interestingly, we couldn’t find SkinVision in the app store. The first that app that came up under a “SkinVision” Search was DermCheck, in which images are submitted to dermatologists (people, not machines) by phone in exchange for a personalized treatment plan—perhaps a testament to some of the kinks in machine learning-based accuracy at scale that still need to be ironed out.
3 – Drug Discovery/Manufacturing
The use of machine learning in preliminary (early-stage) drug discovery has the potential for various uses, from initial screening of drug compounds to predicted success rate based on biological factors. This includes R&D discovery technologies like next-generation sequencing.
Precision medicine, which involves identifying mechanisms for “multifactorial” diseases and in turn alternative paths for therapy, seems to be the frontier in this space. Much of this research involves unsupervised learning, which is in large part still confined to identifying patterns in data without predictions (the latter is still in the realm of supervised learning).
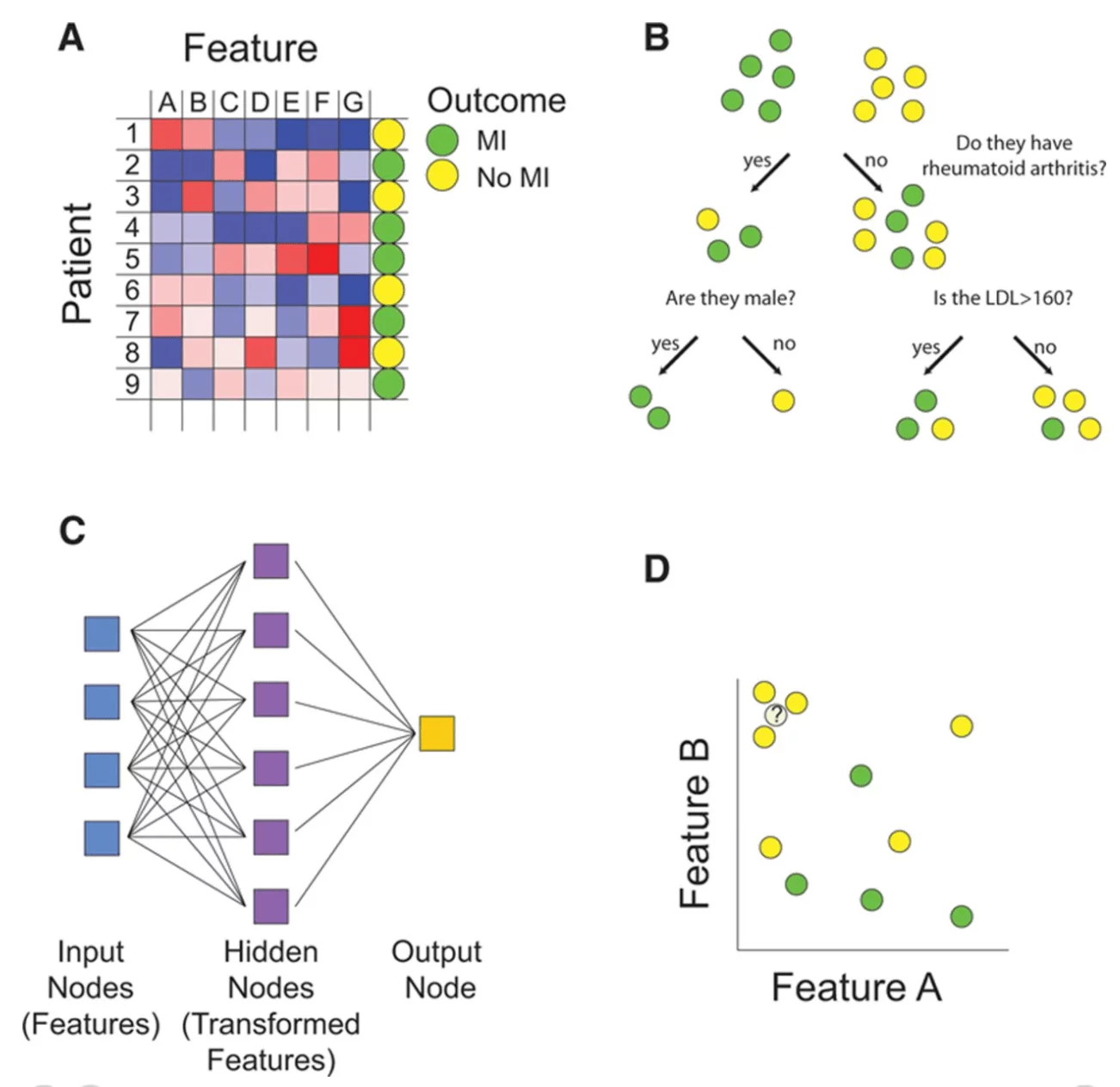 Image credit: Circulation – A: Matrix representation of the supervised and unsupervised learning problem B: Decision trees map features to outcome. C: Neural networks predict outcome based on transformed representations of features D: The k-nearest neighbor algorithm assigns class based on the values of the most similar training examples
Image credit: Circulation – A: Matrix representation of the supervised and unsupervised learning problem B: Decision trees map features to outcome. C: Neural networks predict outcome based on transformed representations of features D: The k-nearest neighbor algorithm assigns class based on the values of the most similar training examples
Key players in this domain include the MIT Clinical Machine Learning Group, whose precision medicine research is focused on the development of algorithms to better understand disease processes and design for effective treatment of diseases like Type 2 diabetes. Microsoft’s Project Hanover is using ML technologies in multiple initiatives, including a collaboration with the Knight Cancer Institute to develop AI technology for cancer precision treatment, with a current focus on developing an approach to personalize drug combinations for Acute Myeloid Leukemia (AML).
Microsoft’s Project Hanover
The UK’s Royal Society also notes that ML in bio-manufacturing for pharmaceuticals is ripe for optimization. Data from experimentation or manufacturing processes have the potential to help pharmaceutical manufacturers reduce the time needed to produce drugs, resulting in lowered costs and improved replication.
4 – Clinical Trial Research
Machine learning has several useful potential applications in helping shape and direct clinical trial research. Applying advanced predictive analytics in identifying candidates for clinical trials could draw on a much wider range of data than at present, including social media and doctor visits, for example, as well as genetic information when looking to target specific populations; this would result in smaller, quicker, and less expensive trials overall.
ML can also be used for remote monitoring and real-time data access for increased safety; for example, monitoring biological and other signals for any sign of harm or death to participants. According to McKinsey, there are many other ML applications for helping increase clinical trial efficiency, including finding best sample sizes for increased efficiency; addressing and adapting to differences in sites for patient recruitment; and using electronic medical records to reduce data errors (duplicate entry, for example).
5 – Radiology and Radiotherapy
In an October 2016 interview with Stat News, Dr. Ziad Obermeyer, an assistant professor at Harvard Medical School, stated: “In 20 years, radiologists won’t exist in anywhere near their current form. They might look more like cyborgs: supervising algorithms reading thousands of studies per minute.” Until that day comes, Google’s DeepMind Health is working with University College London Hospital (UCLH) to develop machine learning algorithms capable of detecting differences in healthy and cancerous tissues to help improve radiation treatments.

Image credit: Google DeepMind Health – radiotherapy planning
DeepMind and UCLH are working on applying ML to help speed up the segmentation process (ensuring that no healthy structures are damaged) and increase accuracy in radiotherapy planning. More on this topic is covered in our industry applications piece on machine learning in radiology.
6 – Smart Electronic Health Records
Document classification (sorting patient queries via email, for example) using support vector machines, and optical character recognition (transforming cursive or other sketched handwriting into digitized characters), are both essential ML-based technologies in helping advance the collection and digitization of electronic health information. MATLAB’s ML handwriting recognition technologies and Google’s Cloud Vision API for optical character recognition are just two examples of innovations in this area:
The MIT Clinical Machine Learning Group is spearheading the development of next-generation intelligent electronic health records, which will incorporate built-in ML/AI to help with things like diagnostics, clinical decisions, and personalized treatment suggestions. MIT notes on its research site the “need for robust machine learning algorithms that are safe, interpretable, can learn from little labeled training data, understand natural language, and generalize well across medical settings and institutions.”
7 – Epidemic Outbreak Prediction
ML and AI technologies are also being applied to monitoring and predicting epidemic outbreaks around the world, based on data collected from satellites, historical information on the web, real-time social media updates, and other sources. The opioid epidemic is a direct example of AI technology being utalized today. Support vector machines and artificial neural networks have been used, for example, to predict malaria outbreaks, taking into account data such as temperature, average monthly rainfall, total number of positive cases, and other data points.
Predicting outbreak severity is particularly pressing in third-world countries, which often lack medical infrastructure, educational avenues, and access to treatments. ProMED-mail is an internet-based reporting program for monitoring emerging diseases and providing outbreak reports in real-time:
Image credit: Going International
Leveraging ProMED reports and other mined media data, the organization HealthMap uses automated classification and visualization to help monitor and provides alerts for disease outbreaks in any country.
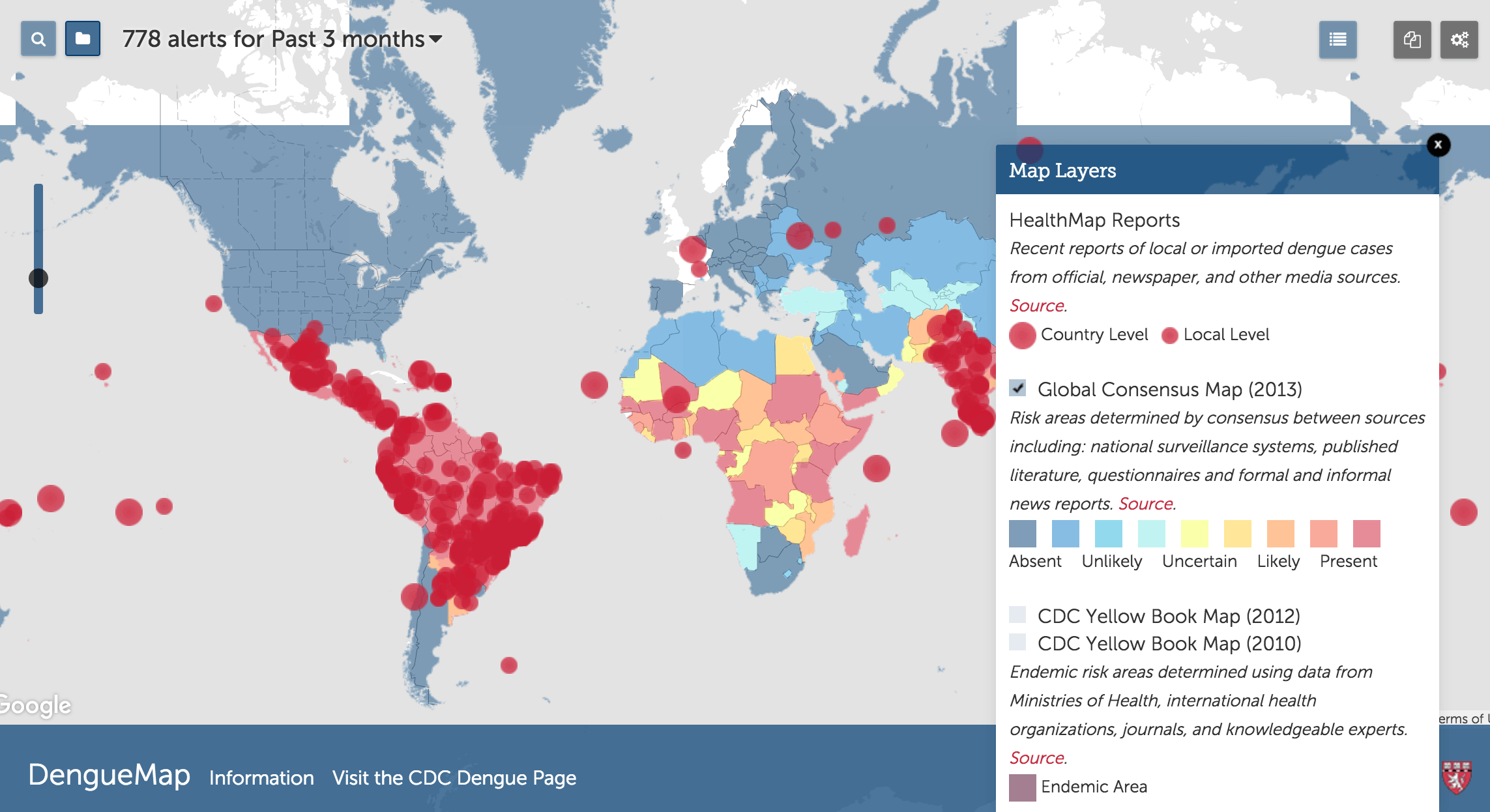
Image credit: CDC — HealthMap report used to track and predict dengue virus outbreaks
Overcoming Obstacles
In the race to apply ML technologies to pharma and medicine, there are major challenges still to be addressed:
- Data governance is one of the most pressing issues to address at present. Medical data is still personal and not easy to access, and it seems logical to assume that most of the public is wary of releasing data in lieu of data privacy concerns. Interestingly, a March 2016 Wellcome Foundation survey on public attitude in the UK of commercial access to health data found that only 17% of respondents would never consent to their anonymized data being shared with third parties, including for research.
- The need for more transparent algorithms is necessary to meet the stringent regulations on drug development; people need to be able to see through the “black box”, so to speak, and understand the causal reasoning behind machine conclusions.
- Recruiting data science talent in the pharmaceutical industry and building a robust skills pipeline is a major necessity.
- Breaking down “data silos” and encouraging a “data-centric view” (i.e. seeing the value in sharing and integrating data) across sectors is of paramount importance in helping shift the industry’s mind-set toward embracing and seeing value in incremental changes over the long-term. Pharmaceutical companies have historically been hesitant to make changes or support research initiatives, unless there is an immediate and significant monetary value.
- Streamlining electronic records, which at present are still messy and fragmented across databases, will be an essential initial step in ramping up personalized treatment solutions.
Emerj for Pharma and Life Sciences Leaders
Artificial intelligence is increasingly finding its way into pharma and life sciences. Pharmaceutical companies are looking to invest in promising AI startups that will give them the edge over their competitors in drug discovery and other R&D processes. They use Emerj AI Opportunity Landscapes to rank AI vendors in pharma and life sciences by how likely they are to deliver a strong ROI in a variety of business areas.
Image credit: Udacity





