


We’ve spoken to many leaders in healthcare and pharma over the last half a decade, and when it comes to AI, the most pressing challenge that healthcare and pharma leaders report is that they’re unsure of how to streamline and structure their data in a way that lets them build machine learning models. Healthcare companies are stuck in the data consolidation phase of their potential AI initiatives while vendor after vendor is trying to sell them on a new application that the company might not even be close to ready for.
AI and machine learning projects can take months to get off the ground. Many pharmaceutical companies don’t start seeing an ROI for half a year or more after launching an AI product if they see one at all. As such, it’s important for pharmaceutical companies to clean and store their data so that it’s “machine-readable,” ready for feeding into a machine learning algorithm when the time comes.
This is likely to save them time and money (thousands even) on an AI product’s initial integration, whether the company makes it in-house or purchases it from an AI vendor.
Zhigeng Chen, Director of Healthcare Big Data Lab at Tencent, had this to say in our interview with him on the importance of working with data (and digitizing it) when it comes to applying machine learning in the healthcare industry:
If you look at that industry, the data is not quite there yet. The digitalization is not ready yet. So for AI, for big data to really take off, that foundation has to be somewhat ready. In the big data domain, we often say 80% of your time or research is spent on data, and then 20% of your time is actually on the models, on the algorithms.
Without that foundation of data and digitalization, it’s hard, or it’s almost impossible to get really good models out of it…without digitalization, without this whole process being online and being digitalized, how are you going to realize or how are you going to bring the value of the AI back to the business?
In this report, we discuss how pharmaceutical companies may be able to aggregate and clean their large amounts of data so that they can make use of it to solve business problems and improve operations with AI, including:
- Centralizing data to be funneled into data science projects and machine learning training
- Preprocessing unstructured data so that machine learning models can recognize and “learn” from it
- Utilizing the centralized and restructured data in data science and predictive analytics for marketing purposes
We begin our report with data centralization.
Data Centralization
A pharmaceutical company’s structured big data is likely stored in a data warehouse of some sort. Pharmaceutical companies may also store unstructured data, essentially that which is not inherently machine-readable, in a variety of places, such as anonymized electronic medical records (EMR) records and databases of medical scans.
Many software vendors offer services to help pharmaceutical companies make sense of all of their incoming data streams in a way that allows them to be fed to machine learning algorithms. Companies selling into the pharmaceutical industry also, in general, seem to offer an API or similar integration that allows clients to run machine learning models either in the cloud or on a company’s computers.
Vendors that offer big data centralization solutions are usually in the AI and data analytics markets as well. They tend to offer data analytics solutions (such as predictive analytics) separately from data centralization, but some offerings may include both. In the pharmaceutical industry, the business problems these vendors most often claim to solve are clinical trial optimization and drug discovery.
One vendor that offers data centralization solutions to pharmaceutical companies is GrayMatter. They also offer a platform on which users can visualize business intelligence analytics.
GrayMatter does not make available any case studies showing a pharmaceutical company’s success with its software, but the company lists Pfizer and Strides Arcolab as past clients. We chose to discuss GrayMatter in this report because their team seems to have a high likelihood of having some experience with AI and machine learning, which bodes well for pharma companies that want to use GrayMatter’s solution to centralize their data for use with machine learning.
Centralizing and structuring data on GrayMatter’s platform might help a pharmaceutical company analyze anonymized EMR records more efficiently in order to narrow down possible patients to reach out to for a clinical trial, for example.
Data integration consultancy and services such as these are for companies that need to centralize their data in order to prepare it for whatever type of AI solution they may want to use. In our next section, we will discuss the preprocessing of pharma companies’ big data and how that data can be prepared for specific machine learning use cases.
Data Preprocessing
During and after all the necessary data is centralized, pharmaceutical companies may need to prepare certain datasets for use in AI and machine learning initiatives. A pharma company’s unstructured data may include drug molecule imaging or EMR data. Data such as this requires labeling before it’s fed into a deep learning algorithm that seeks to “learn” to categorize unlabelled images or fill blank EMR forms, for example.
For imaging data from MRIs or advanced microscopes, each image must be electronically labeled according to the objects and entities that the machine learning model is intended to detect.
For example, microscopic blood imaging software would need to be trained to discern different types of blood cells and how many are present in each image. A machine learning model for blood imaging could also be trained to detect adverse effects and reactions from certain medicines or treatments in the bloodstream.
EMR data is typically written or dictated by a physician. Records include details about the patient and their experience with their illnesses, as well as past medications and treatments for those illnesses and how the patient reacted to them. Natural language processing applications that locate patient information that correlates to clinical trial eligibility are among the prominent solutions for AI in pharma right now.
If a company wanted to build or buy a natural language processing application for sifting through anonymized EMR records for IDC-10 codes to find patients that might be a fit for clinical trials, the EMR records would need to be labeled as containing a certain IDC-10 code or another, for example.
BioSymetrics is one vendor that offers data organization and labeling, cleaning, and analytics for biomedical and healthcare data from diverse sources. Their Augusta application uses machine learning to speed up the process of deploying AI applications in business areas such as drug discovery, clinical trial optimization, and precision medicine.
BioSymetrics’ SymetryML machine learning engine can purportedly evaluate the necessary processing methods of raw data in order to be used in further machine learning development and AI applications. This raw data could be formatted in images, genomics statistics, streaming data, and observed chemical compounds.
SymetryML can process medical imaging data from MRIs and fMRIs. It can also process numerical data from EKG, genetics, proteomics, and IoT data from wearables like the FitBit or a smartwatch. The machine learning model is also able to process information from the EMR format which allows it to combine data from various unstructured sources to develop better products and treatments.
When a chemical compound is rendered digitally as data, it is denoted with an alphanumeric string of text that can be saved for future identification and used for machine learning model training. These chains of text are found through a mathematical formula that can take images and graphical representations of the molecule and turn it into a unique line of code. These codes are known as IUPAC Chemical Identifiers (IChIs).
BioSymetrics does not feature any demonstrations or case studies on its website but does offer examples of how their software can help pharmaceutical and life sciences companies. One of these examples highlights how Augusta analyzed 1.2 million patient variations in association with a certain disease in 155 patients in under 12 minutes.
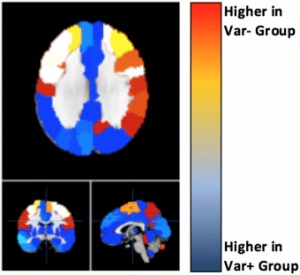
The company was then able to compare medical image attributes on their genetic variants. Figure 2 highlights the distinct regions of the brain that are more affected depending on if the individual has the genetic variant or not:
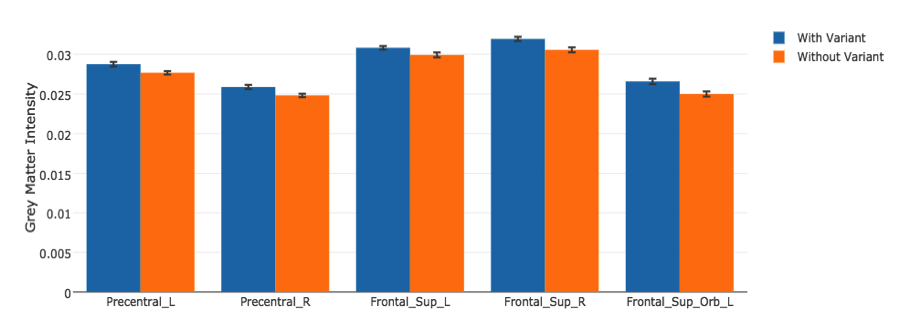
The example states that one of the genetic variants was found to have a significant association with autism in their analysis. The company could then purportedly determine the differences between separate conditions that are associated with a given disease, and who did and did not have this variant based on deviations within separate regions of the brain.
Big Data for Pharmaceutical Marketing
An area where big data plays a particularly significant role in the pharmaceutical industry is in the marketing of their products and treatments to healthcare networks, retailers, and customers. Developing new marketing campaigns, keeping track of ROI and sales statistics, and managing the sales team are all business problems that can be solved with an AI solution which leverages big data.
The data sources that are most relevant to data science initiatives for marketing in pharma are as follows:
- Sales data regarding individual products, geographical sales territories, and retailers
- Both recent and historical market conditions, such as a rise in demand for one product in a certain area while demand for other products falls.
- Data from past marketing campaigns, projects, and experiments, as well as the ROI observed as a result from those campaigns
- Sales team performance data itemized by individual employee and their relative experience
- Data on the customer based separated into demographics and segmented by the continued value each customer is expected to have.
These disparate types of data would likely need to be centralized using a large data storage device and possibly a machine learning solution such as that of GrayMatter. In addition, written information from past marketing campaigns and historical market condition information may need to be preprocessed in order for a machine learning model to recognize it.
It is unclear if the previously-mentioned solution by BioSymetrics would be able to handle these specific types of marketing data.
Complexica is an Australian software vendor that offers a predictive analytics solution called Larry the Digital Analyst. The software is purportedly able to create predictive models for sales rates, marketing investments, and market conditions such as seasonal rises and falls in demand. It is also advertised to optimize sales territory mapping according to the size of the territory, which sales representatives are assigned to which territory, and the geographical location of each.
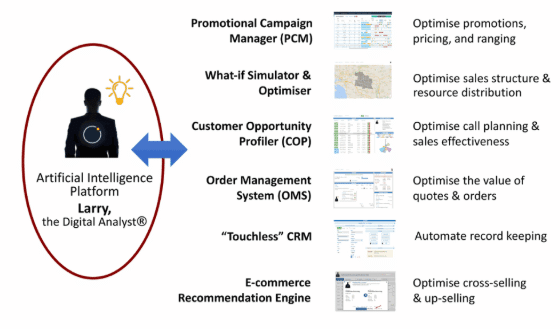
Larry the Digital Analysts acts as an AI platform for Complexica in that it is the AI portion of each of their business intelligence solutions. The graphic to the left details which of Complexica’s software solutions utilize the machine learning model behind Larry the Digital Analyst.
It is unclear if Complexica’s recommendation engine offering for ecommerce also makes use of an actual AI recommendation engine, which would need to exist separately from the predictive analytics abilities of Larry the Digital Analyst.
Though the company does not feature any case studies, their work with Pfizer to help them model sales, marketing investments, and marketing conditions has gained significant attention in the AI space.
Pfizer chose Complexica’s What-If Simulator and Optimizer as their analytics solution, which allowed them to leverage their marketing and sales data to inform their business decisions moving forward.
It is apparent that stores of big data owned by pharmaceutical companies can be used to develop helpful machine learning models for improving pharmaceutical business operations. Though marketing is the clearest business area where enterprise data is being leveraged, pharma companies can utilize their granular medical data for the purposes of clinical trials and drug discovery as well.
Header Image Credit: Scientist Live














{kind=link}
{kind=link}
{kind=link}