
Making AI work has a lot to do with “getting things right” even before a project starts, including:
- Picking the right project
- Ensuring that talent and data resources are sufficient
- Aligning a project with strategic value, not just
Many of these pre-project considerations are unique to AI, and involve new modes of strategic thinking, and new ways of collaboration between teams.
Once an AI project is undertaken, a new set of AI-specific processes are needed. We identify The 3 Phases of AI Deployment and The 7 Steps of the Data Science Lifecycle as two novel dynamics that business leaders and AI project leaders need to understand at a conceptual level.
This article will be the first in a two-part series, focused on The 3 Phases of AI Deployment specifically. But first, we’ll open with an analogy that I’ve often used in keynote presentations for executives, and that I think warrants being repeated here:
AI Deployment as a Living System
Contrary to traditional IT projects, AI projects are living, breathing solutions. They are not static or unpredictable at almost any phase of their deployment – particularly in novel use-cases.
The 3 Phases of AI Adoption involves bringing a data science application from idea to production in a business environment, and the 7 Steps of the Data Science Lifecycle involves the iterative process of finding the right data and model to deliver a specific result.
The 3 Phases of AI Deployment is a linear progression resulting in a deployment where the 7 Steps of the Data Science Lifecycle continuously occur during each of the three phases.
The 3 Phases of AI Deployment
- Description – From proof of concept, to incubation, to deployment, an AI application “matures” by finding a fit between the data, the context of deployment, and the business requirements. Eventually – after iteration, experimentation and questioning – some (but not all) AI applications will reach maturity (deployment) – allowing it to stand on its own merit and deliver business value.
- Biological Analogy: Phases of Development – Not all newborn animals reach adulthood. Competing animals, food scarcity, and changes in the environment pose challenges to survival. Some percentage of animals reach adulthood – still requiring food and shelter but no longer demanding the constant attention of parents. Adulthood could be seen as the third phase of AI Deployment; once reached, the AI project still requires basic resources to remain functioning properly until the end of the project.
The 7 Steps of the Data Science Lifecycle
- Description – The steps of the data science lifecycle progress and cycle through relatively quickly. There is a constant pulse of referring to business requirements, adjusting data assumptions, adjusting features, and iterating on models and workflows in order to arrive at a promising outcome. These seven steps occur within each of the 3 phases of AI deployment.
- Biological Analogy: Breathing and Circulation – The ongoing cycle of steps in the data science lifecycle is like blood circulation, or other homeostatic processes of a biological system. They begin at the very earliest form of the organism’s life, and continue for as long as the organism is alive. If they stop completely, the organism is no longer alive. Just as stopping the 7 steps of data science would result in the AI application no longer delivering any value or results in the business it is implemented in.
The complexity of the biological world is often an apt analogy for AI, especially for business people who are unfamiliar with the unique challenges and processes involved in actually applying AI.
Building an AI application is not “plug and play”, but implies taking care of a living thing, with growing and varied needs.
Stated differently:
- AI is not IT
- AI is probabilistic, not deterministic
- AI is more like R&D than it is like software
- Developing an AI application is life growing and caring for a living, data-fed organism
Many businesses are not prepared for the responsibility, iteration, and upkeep of an AI system, and would be better served by avoiding costly AI research and development (using traditional IT solutions, or more pre-trained vendor tools which require far less iteration and monitoring). It is important for leaders to know what they are getting themselves into before embarking on an AI project.
In the outline below, we explore the components of both the Phases of AI Deployment in greater depth.
The 3 Phases of Enterprise AI Deployment
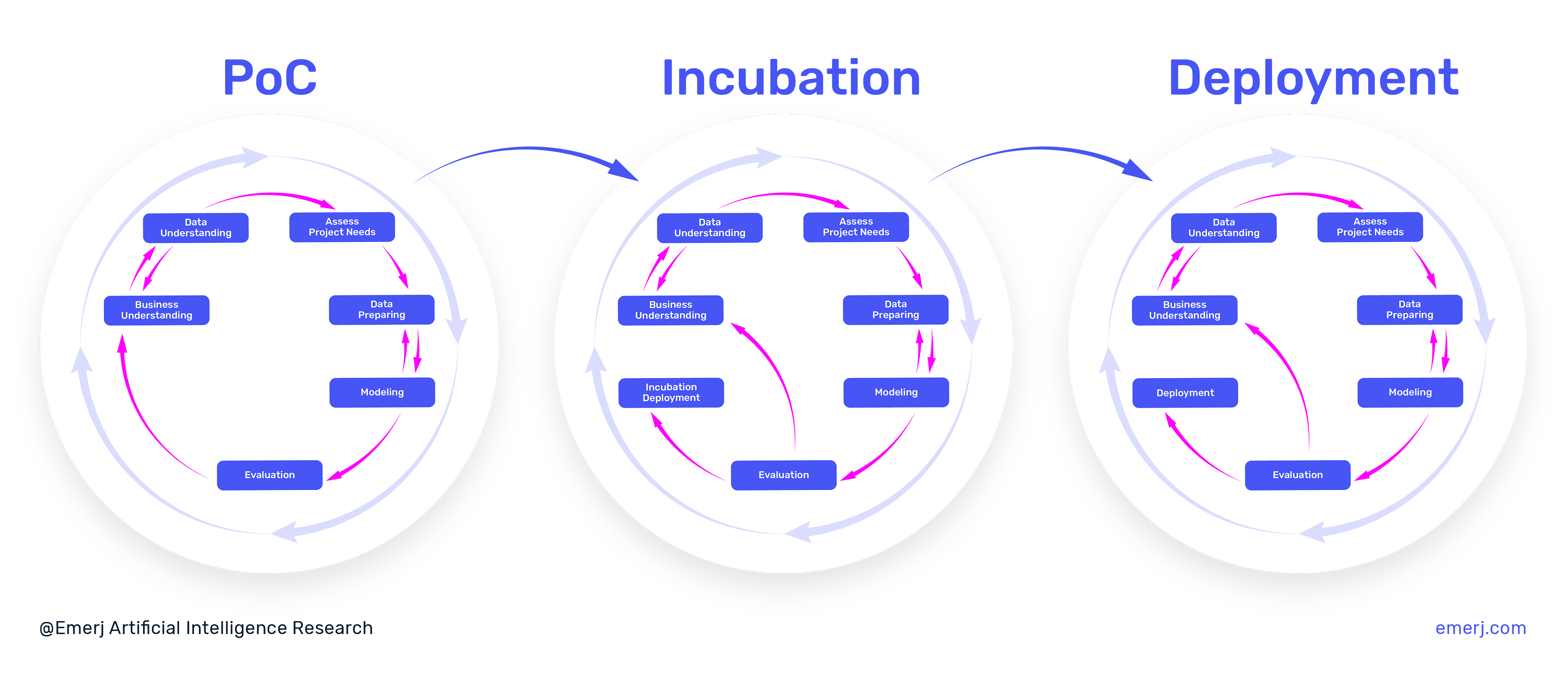
An AI application moves through three phases. Unlike the data science lifecycle, it is unusual for an application to move backwards in phases of deployment, and – ideally – these phases are not cycled through, but progressed through linearly.
We’ll illustrate the phases below with the use of two example companies:
Example 1 – An eCommerce Firm Adopting a Product Recommendation Engine. The eCommerce firm sees promise in improving its cart value and improving on-site user experience, particularly for existing customers with a history of purchases and activity.
Example 2 – A Manufacturing Firm Adopting a Predictive Analytics Application. The manufacturing firm has a strong digital infrastructure and aims to leverage its existing data streams to detect breakdowns and errors in the manufacturing process before they happen.
1. Proof of Concept (PoC)
- Goal – Determine whether or not AI can deliver a specific benefit within one business function (often in a “sandbox” environment with historical, test data).
- Challenges – Determining the right data and features to train on. Selecting problems with a high enough potential business value.
- Criteria for Moving to Next Phase – The application proves that it is capable of showing promising results – reaching some predefined criterion of success) in an isolated “sandbox” environment.
Example 1 – An eCommerce Firm Adopting a Product Recommendation Engine. Use historical purchase, demographic, and behavior data to train a recommendation engine. Have a small subset of users, or in-house staff, assess these recommendations compared to the existing recommendation methods.
Example 2 – A Manufacturing Firm Adopting a Predictive Analytics Application. Use historical data and some real-time data to try and predict breakdowns of one specific kind of machine in the plant (probably, one that we have collected the most data from).
2. Incubation
- Goal – Determine whether or not AI can deliver a specific benefit in a limited, live environment (i.e. real users, real-time data, etc).
- Challenges – Adjusting “sandbox” assumption to the real world, finding a fit within real business workflows (much different than a testing environment), and with real-time data (much different than using canned historical data, or static sample data).
- Criteria for Moving to Next Phase – Predetermined success criteria are reached in the incubation environment. A playbook of how to manage and upkeep the AI application is determined.
Example 1 – An eCommerce Firm Adopting a Product Recommendation Engine. Assuming the initial historical data test worked well – open up the recommendation engine experience to a certain subset of users. This might be done by exposing 15% of logged in users with the new AI-based product recommendation model, while other users see the default recommendations. Take measurements, adjust the algorithm to drive a higher cart value, and adjust and control for issues and errors with this incubation user group.
Example 2 – A Manufacturing Firm Adopting a Predictive Analytics Application. Assuming the initial predictive tests showed promise – instrument a portion of all machines of a certain type with sensors and equipment to help with prediction, and allocate both data scientists and subject-matter experts to determine whether the new predictive methods do a better job of predicting breakdowns than traditional methods.
3. Deployment
- Goal – Achieve a positive business impact in a real business environment – integrating data flow into the AI application, and integration the AI application into actual company workflows, fully replacing the original solution in place.
- Challenges – Training staff and adjusting workflows to account for the new AI application. Maintaining the AI system and vigilantly adjusting the system to account for changing data, a changing environment, and potentially changing or evolving business requirements.
Example 1 – An eCommerce Firm Adopting a Product Recommendation Engine. Assuming the incubation period had fruitful results, and the teams are trained on the new AI-related processes – roll out the recommendation engine as the default user experience, with substantial team dedicated to testing and adjusting the recommendation algorithm, and collecting feedback on its results.
Example 2 – A Manufacturing Firm Adopting a Predictive Analytics Application. Assuming the incubation period had fruitful results, and the teams are trained on the new AI-related processes – instrument all machines of a certain kind with sensors and connectors, creating a central set of dashboards to monitor the machines, and dedicated full-time staff maintaining and improving them.
It’s not important for AI project leaders to entirely understand the technical nuances involved in making an AI project come to life – but it is important for project leaders to come into an AI project with the expectation that they will pass carefully through all three of these stages. The phases of the process have unique milestones and goals, and allow project teams to avoid the risks of hasty integrations, and have sufficient time for iteration and tinkering as the application comes to life. Teams that lack this framework will have a much harder time gauging the effort required to complete a project, and a much harder time seeing projects through to successful deployment.
In the next article in this two-part series, we break down the 7 steps of the data science lifecycle individually, with a special focus on the non-technical elements of the process that lead to actual project success in business. Read that article here: 7 Steps of the Data Science Lifecycle – Applying AI in Business.





