

Netflix launched in 1997 as a mail-based DVD rental business. Alongside the growing US DVD market in the late 1990s and early 2000s, Netflix’s business grew and the company went public in 2002. Netflix posted its first profit a year later. By 2007, Netflix introduced its streaming service, and by 2013, the company began producing original content.
Today, Netflix is one of the world’s largest entertainment services with over 200 million paid memberships spanning 190 countries, according to the company’s 2020 Annual Report. As of January 2022, Netflix trades on the Nasdaq with a market cap that exceeds $260 billion. For the fiscal year ended December 31, 2020, Netflix reported revenues of nearly $25 billion.
The research function at Netflix follows a decentralized model, with “many teams that pursue research in collaboration with business teams, engineering teams, and other researchers,” according to the company’s Netflix Research website, launched in 2018. The company’s research areas include:
- Machine learning
- Recommendations
- Experimentation and causal inference
- Analytics
- Encoding and quality
- Computer vision
In this article, we’ll look at how Netflix has explored AI applications for its business and industry through two unique use-cases:
- Image Personalization for Viewers — Netflix uses artificial intelligence and machine learning to predict which images best engage which viewers as they scroll through the company’s many thousands of titles.
- AVA: Creating Appropriate Thumbnail Images — Netflix has created AVA to source stills from its many thousands of titles that will eventually become the representative images that the company uses to drive viewer engagement.
We will begin by examining how Netflix has turned to machine learning technology to predict the imagery that will resonate most with viewers when they see suggested titles on their Netflix screens.
Image Personalization for Viewers
Netflix has earned its place in the entertainment industry in large part due to its personalized recommendation system that aims to deliver the titles a viewer most likely wants to see at a given time. However, with its extensive library of over 16,800 titles worldwide, according to research compiled by Flixwatch, a Netflix database site, how does Netflix suggest a title’s relevance to a specific member when they are scrolling through hundreds, or even thousands, of offerings?
Netflix research shows that members will invest approximately one minute scrolling through those offerings before they give up. Before the platform loses that viewer to a competing service—or some other activity altogether—Netflix wants to grab their attention. To do this, they’ve turned to the artwork the platform uses to represent each of its titles.
“Given the enormous diversity in taste and preferences,” Netflix asks, “wouldn’t it be better if we could find the best artwork for each of our members to highlight the aspects of a title that are specifically relevant to them?”
Netflix uses the video below to show how, without artwork, much of the visual interest—and engagement—of the company’s experience is removed.
To build much of its platform, Netflix has relied heavily on batch machine learning approaches informed by algorithms that reflect A/B testing results. However, when determining which artwork will resonate with which viewers, this approach results in delays during:
- Data generation
- Model development
- A/B testing execution and analysis
To apply image personalization to its library of titles, Netflix has turned to an online machine learning framework called contextual bandits. Through contextual bandits, Netflix claims, the company can “rapidly figure out the optimal personalized artwork solution for a title for each member and context. … by trad[ing] off the cost of gathering training data required for learning an unbiased model on an ongoing basis with the benefits of applying the learned model to each member context.”
Netflix goes on to explain that they obtain the training data through the “injection of controlled randomization in the learned model’s predictions.”
By considering user-specific factors like viewing history and country, Netflix claims to emphasize themes through the artwork it shows as members scroll their screens. Here Netflix’s then-Director of Machine Learning shows how artwork is personalized for a title like “Stranger Things.”
In another example, the Netflix TechBlog explores how an image is chosen that represents the movie, “Good Will Hunting.” The post explains that if a viewer has a viewing history that includes romance movies, they may see a thumbnail image of Matt Damon and Minnie Driver together. If that viewer watches a lot of comedies, however, they may instead be shown a thumbnail image of Robin Williams.
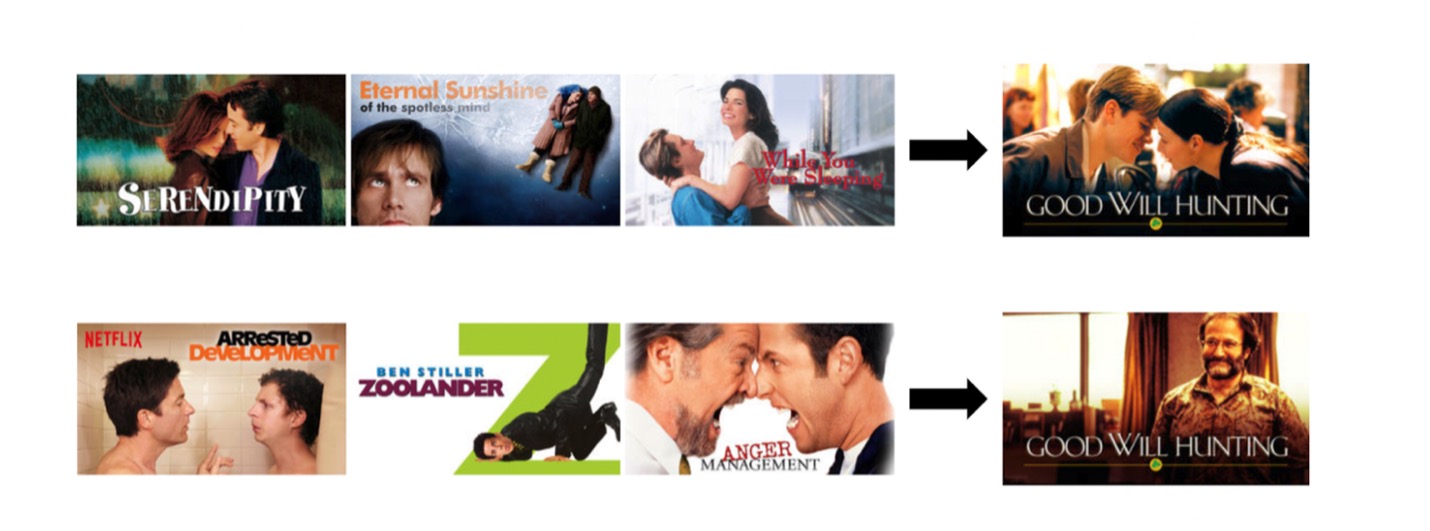
Source: Netflix
While our research did not identify specific results related to increased viewings of specific titles due to these technologies, Netflix does disclose that they have realized positive results through their own A/B testing and that the biggest benefits have come from promoting less well-known titles. Given these results, Netflix is now exploring further customization in how it presents its selections to viewers by adapting on-screen areas like:
- Synopsis
- Evidence
- Row Title
- Metadata
- Trailer
AVA: Creating Appropriate Thumbnail Images
Before Netflix can choose which thumbnail images best engage which viewers, the company must generate multiple images for each of the thousands of titles the service offers to its members. In the early days of the service, Netflix sourced title images from its studio partners, but soon concluded that these images did not sufficiently engage viewers in a grid format where titles live side by side.
Netflix explains: “Some were intended for roadside billboards where they don’t live alongside other titles. Other images were sourced from DVD cover art which don’t work well in a grid layout in multiple form factors (TV, mobile, etc.).”
As a result, Netflix began to develop their own thumbnail images, or stills from “static video frames” that come from the source content itself, according to the Netflix TechBlog. However, if, for example, a one-hour episode of “Stranger Things” contains some 86,000 static video frames, and each of the show’s first three seasons has eight episodes, Netflix could have more than two million static video frames to analyze and choose from.
Netflix soon concluded that relying on the “in-depth expertise” of human curators or editors in selecting these thumbnail images “presents a very challenging expectation.” To scale its effort to create as many stills as possible for each of its titles, Netflix turned to AVA, “a collection of tools and algorithms designed to surface high quality imagery from the videos on [the] service.”
Netflix states that AVA scans each frame of every title in the Netflix library to evaluate contextual metadata and identify “objective signals” that ranking algorithms then use to identify frames that meet the service’s “aesthetic, creative, and diversity objectives” required before they can qualify as thumbnail images. According to Netflix, these factors include:
- Face detection, including pose estimation and sentiment analysis
- Motion estimation, including motion blur and camera movement
- Camera shot identification, including estimation of cinematographer intent
- Object detection, including importance determination of non-human subjects
This Frame Annotation process focuses on frames that represent the title and interactions between the characters, while setting aside frames with unfortunate traits like blinking, blurring, or that capture characters in mid-speech, according to a Netflix Research presentation.

To train the underlying Convolutional Neural Network (CNN), Netflix assembled a dataset of some twenty thousand faces (positive and negative examples) from movie artwork, thumbnails, and random movie frames, the company claims.
The CNN also evaluates the prominence of each character by evaluating the frequency with which the character appears by him- or herself and with other characters in the title. This helps “prioritize main characters and de-prioritize secondary characters or extras,” Netflix claims.
Through its analysis, each frame receives a score that represents the strength of its candidacy as a thumbnail image. Per Netflix, AVA considers the following elements when it forms the final list of images that best represent each title:
- Actors, including prominence, relevance, posture, and facial landmarks
- Image Diversity, including camera shot types, visual similarity, color, and saliency maps
- Maturity Filters, including screening for harmful or offensive elements
While our research did not identify any results specific to AVA’s use within Netflix, the company hopes that AVA will save creative teams time and resources as it surfaces the best stills to consider for candidates as thumbnail images and that the technology will drive more and better options to present to viewers during that crucial minute that viewers allow before they lose interest and search for another way to spend their time.





