

ExxonMobil is the largest investor-owned company in the world and the largest oil company by revenue in the Western world.
According to the ExxonMobil 2021 annual report [pdf], the company realized just over $23 billion in net income on $276.7 billion in revenue. Per the same report, the company employs 64,000 people. According to Google Finance, the company is traded on the NYSE (stock symbol: XOM) and has a market cap of $420.1 billion.
A LinkedIn search for data scientists at ExxonMobil yielded 668 results. Regarding AI adoption, Exxon doesn’t reveal many public details. While a Google search uncovers quite a few AI applications supposedly in use by the company, very little data is provided.
In this article, we will examine two applications at ExxonMobil that exemplify how AI capabilities support the company’s business goals:
- Predictive maintenance: ExxonMobil expedites the oil analysis process and reduces clients’ labor costs using proprietary laboratory software combined with machine learning.
- Expediting well development: ExxonMobil uses AI to integrate data silos, enabling the faster development of oil wells.
We will also discuss the business value of these applications in a pragmatic way, with the aim of arming leaders with actionable guidance.
Application #1: Predictive Maintenance
Predictive maintenance (PdM) – determining equipment condition to schedule timely maintenance – is a regular practice of the extraction industry and has been for at least two decades. However, the implementation of machine learning has augmented this process by providing “operators and engineers with improved foresight,” according to the Journal of Petroleum Technology (JPT).
Drilling sites have hundreds of simultaneously-operating pieces of equipment running 24/7. This equipment is complex and, therefore, expensive and time-consuming to repair. Performing predictive maintenance on these assets can not only prevent unplanned downtime but extend the life of a costly asset.
As such, PdM is a cost-savings measure. Costs are reduced by performing maintenance tasks only when necessary. PdM serves to prevent the average 27 days of unplanned downtime – and $38 million in losses – experienced by the average oil and gas company, according to a JPT article.
ExxonMobil offers a “Mobil Serv Lubricant Analysis” service that the company claims can reduce scheduled downtime, lubricant consumption, and costs while enhancing equipment reliability.
The company purports to accomplish this by faster-obtaining rig equipment’s oil analysis (OA) using a proprietary analytics platform featuring machine learning algorithms. OA is a laboratory analysis of lubricant properties, suspended contaminants, and wear debris that serves to provide insight into the machine’s condition.
According to the MobilServ website, the laboratory tests conducted in its solution use two AI-assisted components:
- Logic algorithms paired with an “extensive used-oil analysis limits database” on various equipment and engines.
- An engine that weighs model output against user-provided equipment data to produce actionable recommendations (See the “Recommendations/Comments” sections in Figure 2 for an example.)
According to product documentation [pdf], the program works as follows:
- The user registers for the program and provides details on their equipment.
- MobilServ mails sample materials, including QR tags that are placed on the sample bottles and the equipment, pairing them for analysis purposes.
- When the user submits a sample, they use the mobile app’s QR code scanner and scan the bottle and equipment tags.
- The user enters equipment operation details (e.g., date, hour/miles/kilometers, etc.).
- The user packs and mails the sample.
After the laboratory receives the test samples, results are typically available within 24-48 hours.
The user accesses test results in the form of color-coded reports on the online platform. The report is also available via email or fax upon request. The report contains the following data (see figure 1 for a detailed report):
- Equipment Information
- Sample Information
- Account Information
- Sample Data and Trends
- Lubricant Data
- Equipment Wear Data
- Contaminant Data
- Additive Data
- Recommendations/comments
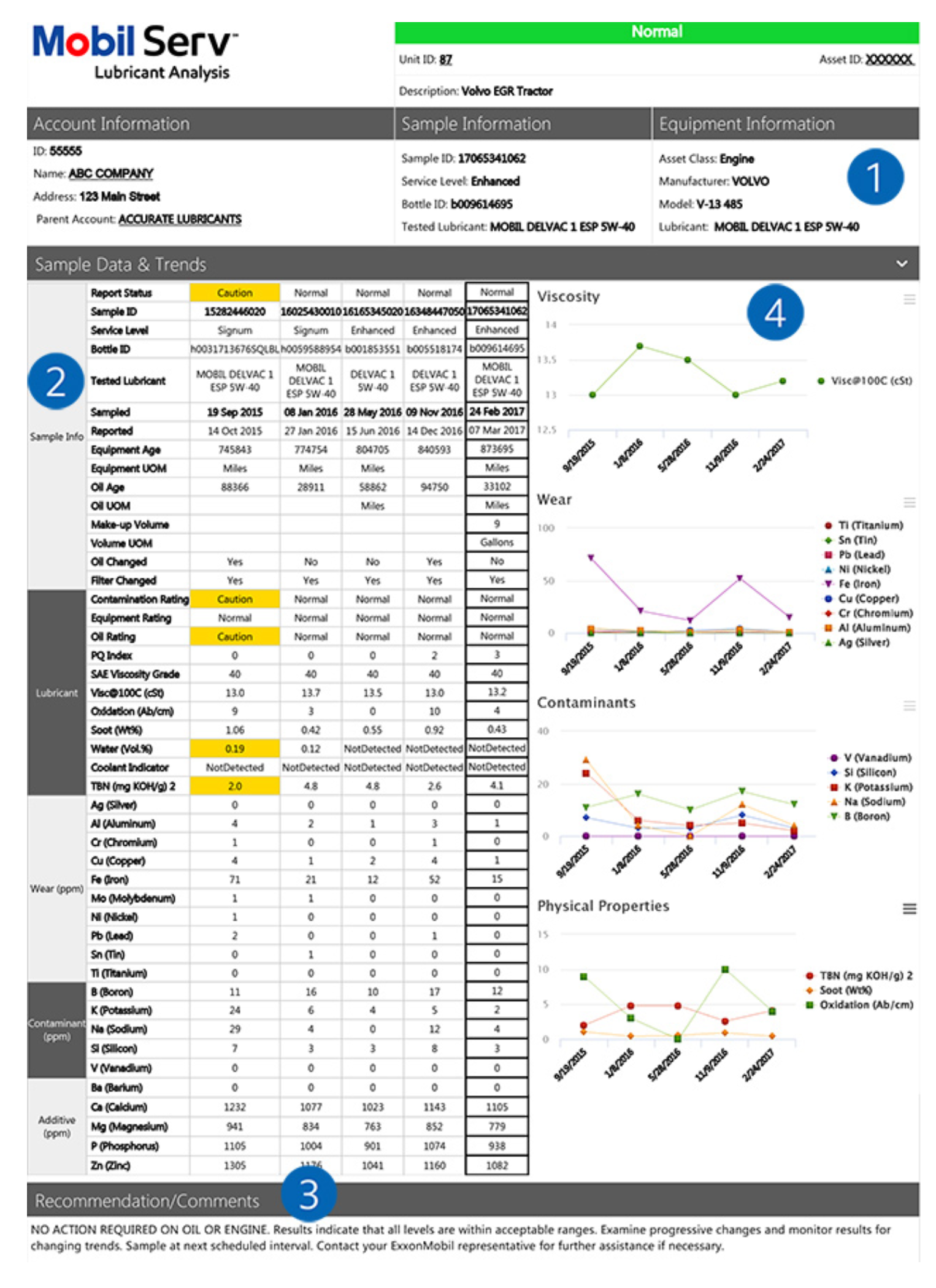 Figure 1: MobilServ Lubricant Analysis Report (Source [PDF]: MobilServ Lubricant Analysis Guide)
Figure 1: MobilServ Lubricant Analysis Report (Source [PDF]: MobilServ Lubricant Analysis Guide)
The following one min, 25-second video is of ExxonMobil’s value proposition for its Mobil Serv Lubricant Analysis solution:
In one case study [PDF], ExxonMobil worked with an unnamed alumina production company based in Texas. The company obtains over 150 OA samples per the report as part of its preventative maintenance program. According to EM, the manual process of collective and labeling samples required the following:
- The equivalent of 24 labor hours per month
- SMEs to spend an excess time on tedious tasks, such as printing and filling out sample labels
Per the report, the company experienced the following business results:
- 66% reduction in monthly sample collection time – the equivalent of 16 labor hour
- An annual savings of $9,600 in labor costs
Application #2: Expediting Well Development
Oil companies are invested in seismic interpretation because the technology can unearth promising, less-explored areas for oil discovery and thereby increase production and revenues.
ExxonMobil has been conducting seismic interpretation in the Gulf of Mexico for nearly a decade. According to ExxonMobil Digital Transformation Lead Dr. Xiaojung Huang, the traditional method of seismic interpretation is arduous and time-consuming. As a result, the company was dealt the following business and technological challenges:
- Data that was siloed in hundreds to thousands of applications, resulting in complex and time-consuming data collection and organization
- A data infrastructure incapable of expediting project development
- A need to expedite ROI on a multi-billion-dollar offshore oil discovery project
The company had invested multiple billions of dollars in a new offshore oil discovery in Guyana. EM required:
- A modern data platform that could enable AI and workflows
- A data infrastructure capable of speeding up project development in the region.
At the nucleus of the problem was EM’s inability to connect data silos. These data were needed to apply AI to seismic interpretation to accelerate development well planning. Dr. Huang states in a video that “seismic interpretation typically takes anywhere from twelve to eighteen months.”
However, she concluded that AI could cut this time in half. To do so, EM would need to integrate a capable data infrastructure. “We can not scale anything up if we do not have a developed data foundation,” Huang also says in the video.
The data foundation required the amassment of multiple disparate data sources into one integrated platform.
What followed was a 12-month collaboration between the seismic experts at EM and a data science and AI team at IBM. IBM concluded that they could build a single data repository using open-source technologies. To accomplish this, 20 EM SMEs in various disciplines first worked with the IBM team to construct a series of workflows for a small drill well planning project.
It is stated that these different data workflows needed to be combined using an IBM-recommended open-sourced, AI-driven process. While not stated in the documentation outright, we may deduce from there that the process involved IBM’s Cloud Pak for Data. The tool packages two essential tools for data integration: machine-learning-enabled data virtualization and confidence-based querying.
The approximately-2-minute video below demonstrates some of the features of Cloud Pak for Data and how they relate to AI deployments:
Connecting data at the platform level would have required the team to:
- Type the connection name and connection type into the Cloudpak for Data platform
- Specify the network configurations
- Test and verify the successful connection between databases
- Unify the various databases via the creation of a single, searchable repository
As a result of this new AI-enabled data management platform, ExxonMobil reportedly realized the following business outcomes:
- A two-month reduction in drilling design planning for new wells (nine to seven months).
- 40% less time spent on data preparation





