
“Machine learning” is a term that’s heard more often in startup and big data circles than “artificial intelligence”, and interestingly enough, Google Trends confirms what’s already heard through the technological grapevine:
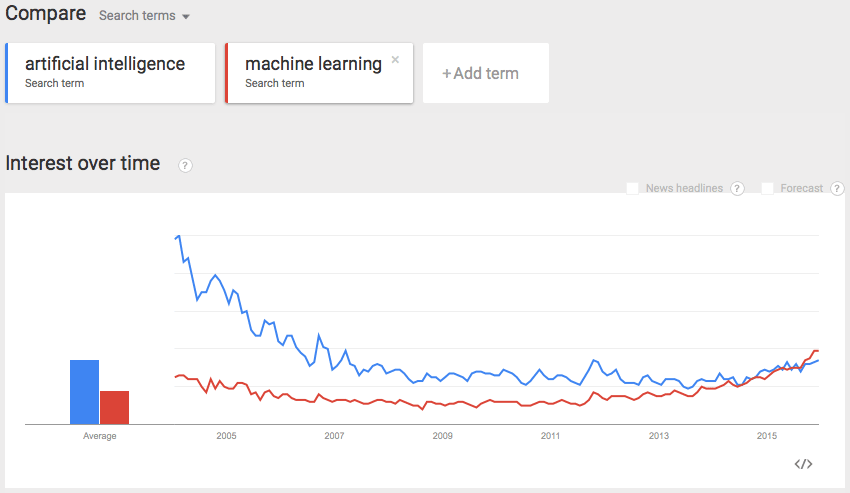
Image credit: Google Trends
While most business laypeople have heard the term, they’re more interested in what machine learning (ML) can do, as opposed to how it works.
While it could be argued that both are important – even for business people – this article will focus on five current applications of ML that are likely to be important parts of an expanding trend.
(Note: For a reasonable understanding of the basics of machine learning, you don’t have to take Stanford’s full Coursera class, this short SciPy talk is a good start, and this article on Emerj is a nice overview for the general educated public).
1 – Recommending Systems
Most of us are familiar with Amazon’s now-famous, ubiquitous “you might also like…” These suggested products aren’t merely based off of randomizing products in a similar category and putting them up as a “best shot,” those suggestions are the result of millions and millions of online transactions through Amazon’s eCommerce platform – crunched and analyzed to discern what a user like you (geography, account history, engagement on the page, cart value) might like.
Given the 200-and-something million products that Amazon offers, that’s far too much information for a human being to calibrate individually over the course of 200 years, never mind in real time.
Companies like Pandora and Spotify are also famously employing recommendation engines, undoubtedly contributing to their success in the domain of streaming music. Netflix ran it’s Netflix Prize contest in 2009 in order to test the effectiveness of multiple algorithms for predicting someone’s likelihood of enjoying movies, and the company focuses incessantly on minute feedback from user’s engagement with films in order to suggest the best possible content for each individual user.
Moving forward, recommendation engines will become more and more prevalent as companies compete on the most engaging and personalized user experience. Recommendation engines may do more than help people pick music, artwork, food, or movies. Future recommendation engines may tell software users which features they should try next (given the problem they’re trying to solve), or even help managers delegate work more effectively to their team (given historical team performance and workloads).
Like most any other application of machine learning, these applications require rather large amounts if data and relatively nuanced skill sets – potentially putting the advantage in the court of large companies like Netflix and Amazon.
2 – Autonomous Vehicles
There’s a lot that goes into building a self-driving car, but there’s a single most important thing that comes out of it: Data.
In order to have their autonomous vehicles drive so seamlessly around the streets of Mountain View, Google employs a variety of strategies, including an analysis of activity (speeds, acceleration, turning, etc…) of past drives, a variety of sensors that detect changes in the environment (people, other vehicles, red lights, etc…), and interaction with a made-to-scale model of Mountain View’s streets (which has been painstakingly measured, all the way up to the heights of the curbs and distances between them).
After 50 left turns at a certain intersection, Google’s cars (all of them, not just the one that made the last turn) learn more and more about not only how to master that one left turn, but about how to master similar left turns in relatively similar contexts (based on the activity of other traffic, the road conditions, weather, and more). Machine learning lets all of these moment-to-moment experiences translate into a data file of driving mastery.
The Atlantic composed an interesting article about how Google’s cars function (in layman’s terms).
Elon Musk and others predict self-driving cars being commonplace within half a decade, while others are less optimistic that the legal considerations (if not all of the technical considerations) will be viable within that time. Regardless, with nearly all major auto makers investing heavily in the future of vehicle autonomy, we can expect many a machine learning specialist grinding away at Ford or Nissan or Tesla for years to come – and the resulting influx of more and more vehicle data will only make the technology better.
3 – Computer Vision / Perception
When it comes to recognizing faces, Facebook almost doesn’t need you anymore. Maybe it did a while ago, but no more (thanks to DeepFace).
As human beings, facial recognition isn’t second nature, it’s nature (we have a brain region roughly dedicated to this task). So why has it been so difficult for computers? As it turns out, many of the early approaches to matching features to people just don’t work out well. Differences in illumination, facial hair, and angle of the camera make it difficult to identify people based on previously identified photos (MIT’s Patrick Winston explains these previous approaches very well at around 30 minutes into this video).
Facebook’s DeepFace makes an estimate of a 3D face even if it only has access to 2D images. It wasn’t programmed to find faces, it learned to find faces, thanks to oodles of data. Nearly a billion Facebook users have tagged countless images with the faces of other users for years, so Facebook has a data set of faces from all kinds of angles and perspectives, allowing for a tremendous pool of data to train a computer to pick up faces from many angles.
Recognizing faces is far from the be-all-end-all of computer perception.
Future Siri-like assistants might take in visual data in addition to auditory data, reading your lips in order to get a sense of what you’re saying in a noisy environment. Computers of the future might be able to label videos minute-by-minute, not just my what objects are being featured or by what is being said, but by what is actually happening. Companies of the future may be able to do away with ID cards and let security cameras do the job of logging time of individual team members, and notifying staff if an unidentified person is seeking entrance.
All in all, machine learning’s applications are thriving today like AI never has before in industry, thanks to a general increase in computing power, a massive swell of AI talent and fresh interest in the field, and (maybe most importantly) from huge collections of data that can be used to train systems to produce new results.
As more and more high school students are taught to program, and more and more traction is found in various industries, we can expect to see machine learning continue to expand. IBM banking on branding itself around “cognitive” computing, and though it’s Watson suite isn’t the company’s main breadwinner today, they’re hoping that it’ll be the backbone of many of the machine learning applications that the coming decade will bring.
Header image credit: Cisco




