


Professor Jonathan Tapson is Director of the MARCS Institute for Brain, Behavior & Development at Western Sydney University in Australia. He holds a PhD in Engineering from the University of Cape Town in South Africa. Professor Tapson’s recent research has recently lead him to apply neural networks to problems in finance. See our partnership and thought leadership publishing options on our Emerj partnerships page.
Last month, we found out that Google’s DeepMind AI had learnt how to play chess to a superhuman level, in the space of four hours – and without any of the tedious learning of openings and endgames that characterizes human chess strategy. The programmers fed in the rules of chess and had the AI play 44 million games against itself, learning as it went. The result was described by grandmaster Peter Heine Nielsen as follows:
“I always wondered how it would be if a superior species landed on earth and showed us how they played chess. Now I know.”
At the same time that AI is making superhuman game-playing possible, we have become accustomed to the idea that crowdsourcing is also a magic bullet for previously intractable problems, such as mapping the traffic flow and congestion in cities in real time; or designing everything from Lego toys to McDonalds hamburgers.
The idea of crowdsourcing AI, or machine learning, which is what engineers prefer to call it, has been successfully explored by companies such as Kaggle and CrowdAnalytix. They generally use a competition format to involve hundreds of teams of machine learning practitioners in solving big data problems for organizations as diverse as GE and the Department of Homeland Security. Over half a million data scientists have worked on Kaggle problems, and prizes have been as large as three million dollars; the company was acquired by Google in March this year.
Not surprisingly, the idea of using crowdsourced AI to produce superior results in the financial markets has taken off, and there are several startup companies using different models to achieve these. Perhaps the most straightforward is Quantopian, which provides a stock data, analysis and testing platform, and encourages the crowd to come up with equity trading algorithms. Algorithms which make money (and meet a stringent set of performance criteria) may be funded with Quantopian investors’ funds, with the algorithm inventor taking a share of the profits. The number of data scientists using Quantopian’s platform is apparently over 100000, and perhaps as high as 140000.
A similar pattern is followed by Quantiacs, which trades in commodity futures, and runs a quarterly competition. The winning algorithms in each quarter are funded with Quantiacs investors’ money, and again the algorithm designer shares the profits. Quantiacs claims to have over 6000 quants writing algorithms, and has apparently invested around $15M in crowdsourced algorithmic trading strategies.
Perhaps the most out-there venture is Numerai, a company that has been described as “conceptually a work of art”. Richard Craib’s company provides the crowd with a completely sanitized and encrypted data set each week; it is implied that the data are derived factors from a global equity trading strategy, but the crowd has no idea what the data actually represent. Crowd members who contribute the best classification algorithms are rewarded with a combination of cash and Numerai’s Ethereum-based cryptocurrency token, called Numeraire. In October 2017, Numerai claimed to have 30000 data scientists involved in their company.
Given all this excitement and enthusiasm, it takes a certain amount of courage or foolhardiness to come out and say: I don’t think crowdsourced AI is going to work for hedge funds, or at least not in its current forms. The reasons why are important, because they are not unique to the financial markets. Machine learning (ML) has been staggeringly successful in certain classes of problems in which the advantages of the current ML approach outweigh the weaknesses, but the nature of financial investing exposes the weaknesses quite dramatically.
Before I unpack these weaknesses, it’s not unreasonable to ask: how are the crowdsourced ML hedge funds doing? There’s not much data on that, but this is what is visible:
- Quantopian’s results were described as “disappointing” by the UK Financial Times in November 2017; the fund was down by 3% since June 2017. Given that the NYSE was up 5% in the same period, the description probably qualifies as British understatement.
- Quantiacs results are not reported as a fund, but the investments made in the winning crowdsourced algorithms are reported on the website, as is their subsequent performance. If one assumes that the day that the investment allocation in each algorithm was reported was the initial day of trading for that algorithm, and that none of the investments has been liquidated, it’s not a pretty sight. They have invested nearly $16M in the form of about $2.25M per quarter for 7 quarters, for an absolute return of $0.145M; the average quarterly return of the invested algorithms is 0.3%. Nearly half the investments have negative or zero growth, and only one is more than 10% positive. Only one funded algorithm has a Sharpe ratio greater than one. Sharpe ratio is a standard measure of risk-adjusted profitability of a strategy, and a ratio of one might be considered a threshold between a mediocre and a solid performer. Almost all the invested algorithms had a Sharpe ratio much greater than one in both backtesting and live forward testing, prior to investment.
- Numerai has claimed to be “making money”. It’s hard to establish what that means. They took a second round of venture capital in December 2016, which may or may not be good news. Their strategy of paying out in an Ethereum token got a massive boost from the boom in cryptocurrencies, so (unlike Quantopian and Quantiacs) their “crowd” does actually seem to be benefitting on a wide scale. On the other hand, if one views the lifetime earnings of the best crowd members, one sees a phenomenon that is also visible in the other companies – the early high performing data scientists have dropped out, and no-one appears to be making a first-world living here (even at the level of, say, driving for Uber). Numerai’s total weekly cash reward is $6000, split unevenly amongst the week’s top 100 data scientists; I don’t think anyone’s giving up their day job just yet. However, for reasons I’ll touch on later, they may be making the most sensible use of ML in this sector.
While this is not precise information, one gets a strong impression that these funds are not shooting the lights out, in the way that you would expect a ground-breaking strategy to do. One expects in both tech and finance that a good play should display some early-mover advantage, either in adoption or income, and that’s not visible here. There would have to be a dramatic improvement in performance for anyone to be convinced that these are the harbingers of hedge fund disruption.
So, what is the problem? It has three facets: the data, the process, and the crowd numbers. The data is the most visible issue. Financial data is utterly different to the data on which 99.9% of machine learning research takes place, and on which all machine learning students are taught. Machine learning is deeply rooted in academia, and even the big corporate efforts are headed up by “rock star” professors such as Yann LeCun (Facebook) and Geoffrey Hinton (Google).
Academic progress in ML is defined by the performance of new algorithms on widely available benchmark data sets. For example, for the last six or seven years, it would be very hard to promote a classification algorithm that did not offer a near state-of-the-art result on the two CIFAR image data sets, which consist of 60000 images of objects such as vehicles and animals; the task is to classify the object in the image.
A typical image from CIFAR-10 is shown in below. Below it is an equivalent piece of financial data – Apple, Inc.’s daily share price for the entirety of its history.
Figure: A typical image from the CIFAR-10 data set – 32x32x3 color image, requiring a simple answer to the question “what is it”.

Figure: Apple’s daily share price (adjusted for splits etc.) since listing. What will the price be N days into the future?
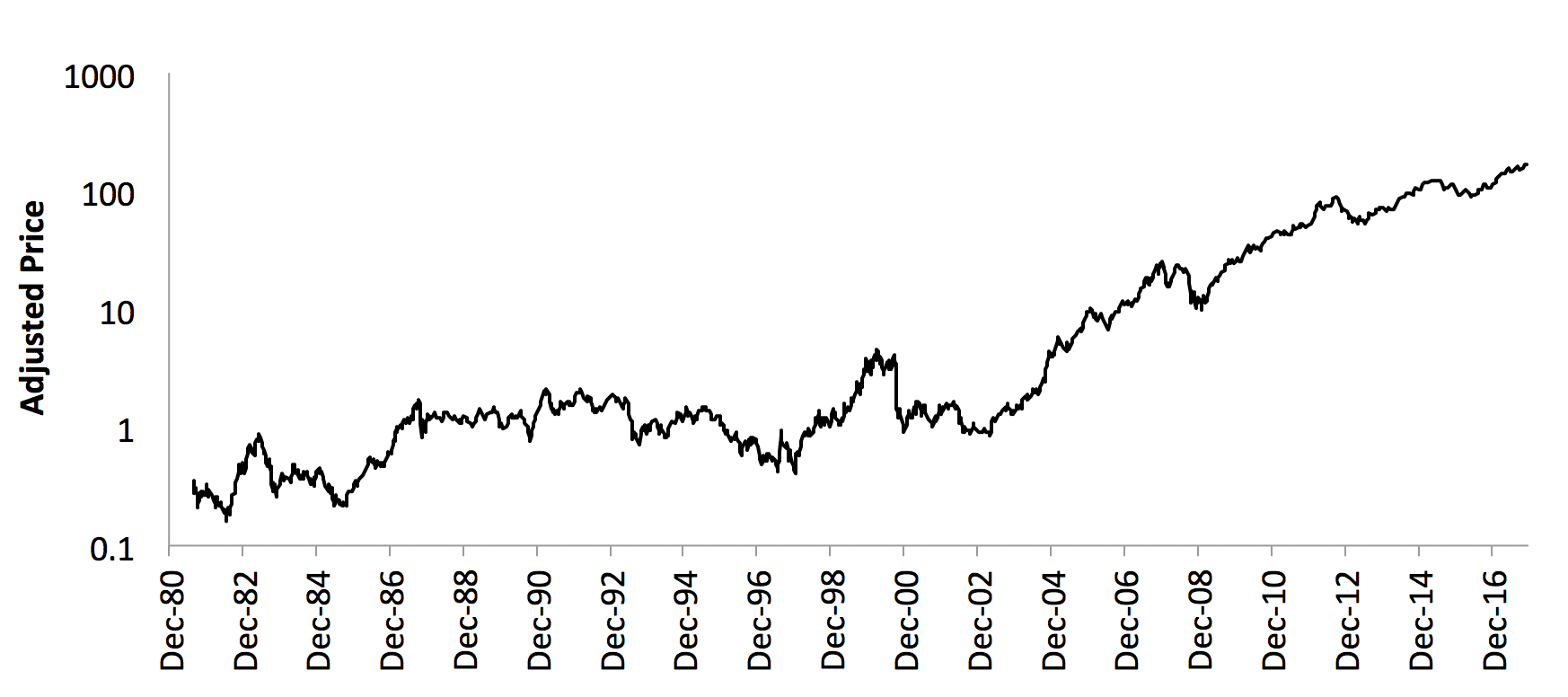
Here are some key departures between these types of data:
- The CIFAR sets are static and complete – they will never change, and the relationships between their elements are fixed for all time. The entire data set is visible to researchers, whether or not they choose to use the conventional subsets of testing, training and hold-out data.
- Even though the image sizes were reduced to just 32×32 pixels to make the dataset manageable, the CIFAR datasets are large – 183 million data points – which are processed to answer a single, unchanging question, with either ten or a hundred unique answers.
- The CIFAR data sets have 100% labeling (labeling refers to the existence of a label for each image, describing what the perfect answer to the simple question is).
- Apple’s daily share price data has just 9333 data points – one per trading day since it listed on December 12, 1980. If one expanded this to one-minute-resolution data, it would still be only 3638700 points – about the same as a single low resolution photograph. Financial price series are not big data.
- Apple’s price has been driven by internal corporate events (the firing and re-hiring of Steve Jobs; the launch of iPhones) and external financial events (the dot.com boom and bust) and geopolitics (the rise of China). It is a response to 37 years of complex interactions with real-life events.
- We know with certainty that the statistics of Apple’s price series are non-stationary, and a complete analysis of the data to date would not be a good indicator of the data still to come.
- There is no perfect answer to the question, “Should I have bought Apple shares on a given day?” even within the perfect hindsight of historical data. Modern portfolio theory notwithstanding, most investment questions can be accurately answered by “it depends…”
The issue of non-stationary data deserves some unpacking. The daily dollar volume of shares traded on the NYSE is about 2% of the total NYSE capitalization, implying about 500% turnover per annum. This suggests strongly that trading occurs not to own equities, but to profit from trading them; which (in case anyone was in any doubt) suggests that the price of equities is strongly determined by the trading behavior of traders.
During the four decades of Apple’s existence, trading strategies have become much more sophisticated; returns from trading strategies such as mean reversion have fallen from being extremely profitable to negligible levels as they have become widely adopted. Mean reversion is a kind of statistical arbitrage which works, or doesn’t work, as a function of the distribution and correlation of randomness of price movements. The statistics of equity prices are therefore also a response to the mass of traders who have found, for brief periods of time, profitable strategies to exploit them. Any statistical regularity in the price will be exploited until it no longer exists.
Exploiting statistical regularities in price data is somewhat like trying to grab a wet bar of soap; the act of seizing them causes them to go someplace else. In the case of mean reversion, it took four decades for the regularities to be tuned out of the market by constant exploitation, but this process has accelerated dramatically with the advent of algorithmic trading.
This is old news to traders, and risks a digression into the efficient market controversy, which we will avoid. The issue for ML is that there were exploitable structures in the historic data that are most likely non-existent now. It is a basic dogma of ML that naïve training works best (i.e., not constraining models with human-derived heuristics, such as a catalog of chess opening sequences, or extracting high level features); but it is extremely hard to direct an ML system to ignore apparently profitable actions.
One might attempt to address this problem by confining the learning to say the most recent year of price data. Then you have just 252 data points to work with, which makes the data problem even worse.
One might ask: what about all the data other than share prices – iPhone sales numbers, the price of the raw materials of electronics, exchange rates, the sentiment towards Apple expressed on twitter – that could be measures of factors that drive Apple’s price? Isn’t the essence of big data to extract the truth from a vast data space?
Unfortunately, if we try and project from millions of data sources to our scant price data, the problem is profoundly ill-posed; there will be many variables or combinations of variables in the big data which co-incidentally correlate with Apple’s price. It could be that for the space of the last year, the product of daily rainfall in Uzbhekistan multiplied by the daily number of births in Lagos forms a perfect leading indicator of Apple’s share price; but using that to predict tomorrow’s price is unlikely to be helpful.
I am not suggesting the situation is hopeless, but am pointing out that blind application of methods that have scored well on image sets may produce excellent back-test scores, without much live trading success.
What about the time-honored ML method of using a hold-out data set? This brings us to the second problem, process. ML data sets are almost always divided into training sets and test sets, so that the algorithm is tested on previously unseen data (data that it has not been trained on). There is sometimes also a hold-out data set, reserved for a final test once the algorithm is set in stone. All of these together are supposed to save us from over-fitting – the process whereby the algorithm learns to respond to the minutiae of the training data set, rather than learning a general structural relationship that will extend beneficially to unseen data.
It has only recently become acknowledged that data science suffers from the same problem that the social sciences call “p-hacking” – the process of changing the question until the data gives you a statistically significant probability, p, of a correct answer. The ML form is called hyperparameter tuning – changing the structure and biases of the neural networks to find the fine-tuning that gives the best answer, as revealed by the test data set.
The social sciences counter this with the Bonferroni method – a formula that says in effect: the more hypotheses you test with your data, the more accurate the answer must be before you can claim a particular level of statistical significance. There is as yet no widely accepted ML criteria to say: the more you tune the hyperparameters, the more accurate your answer needs to be in order to claim improvement. (Each set of hyperparameters is a hypothetical model being tested on the data.) In fact, there is no consensus that this is even a problem; most academic claims of superior performance on a data set make no reference to the extent of hyperparameter tuning used.
I think it is no coincidence that some of the most lucid work on this problem in ML comes from Marcos López de Prado of Guggenheim Partners, whose fund may be one of the few that is successfully applying machine learning to equity trading. They have proposed a “Deflated Sharpe Ratio” to address this problem, but I don’t see anyone using it in the ML quant community.
Hyperparameter tuning is a strangely addictive process; you can sit for hours, adding a neuron or feature, or changing a gain, searching for that elusive 0.1% improvement on the test set. Most ML software packages now have a built-in hyperparameter search function, so all it takes is a line or two of code. The majority of ML academics would be appalled if it was suggested that this process was “cheating”. That is an academic debate that is starting to happen; but back in the real world, with parsimonious data flows, there is no doubt that it leads to overfit algorithms.
As Moritz Hardt has amusingly shown, it is possible to get a top-10 leaderboard position in a Kaggle competition without ever looking at the training data set at all, but simply by fine-tuning a random-number submission for the test set. In the Kaggle format, this should be found out or exposed in the final test against the hold-out data. In crowdsourced ML hedge fund strategies, it should be exposed by a live trading test.
That leads us to the third problem: the numbers – the tens of thousands of data scientists who contribute trading algorithms to the funds. Nassim Taleb may have been first to point out the fallacy of assuming that a leading hedge fund has an intrinsically superior strategy. If you have thousands of hedge funds, the year’s top performer will most likely be in that position by dumb luck, their stock trading decisions the equivalent of flipping a coin heads-up many times in a row.
By the same token, if we take thousands of over-fit algorithms, each of which has excellent back-test results, and trade them forward for three months (which is just sixty trading days) there will undoubtedly be some that trade forward with excellent results. There is no reason to expect those ones to continue to do well; the longer the live test, the more chance they will be eventually exposed as simply having been lucky (for a while). Judging by the performance of Quantiacs investments, the algorithms seem to fall over at the moment some real money is invested.
Numerai may be avoiding this problem by very tightly defining the investment strategy, so that the ML solution is used simply to fine-tune their portfolio decisions. In this case, the crowd would act as a “committee of experts” and their aggregate decision might not be overfit. The Numerai ranking function rewards solutions which are uncorrelated to the rest of the crowd, which would reinforce this outcome.
On the other hand, by pre-defining the strategy, they do not get the hypothetical “let a thousand flowers bloom” benefits of using the crowd to explore the full space of investment possibilities, and their upside is capped to the optimal performance of a predefined strategy. Richard Craib has written “the difference between crowdsourcing machine learning vs crowdsourcing quant is not subtle”, which suggests this approach is quite deliberate.
To summarise, the problems of crowd-source hedge fund trading are as follows:
- Blind application of successful ML algorithms to trading data is problematic because trading data is not statistically stationary nor extensive enough for the popular methods to work.
- Overfitting of algorithms by meta-processes such as hyperparameter tuning is not generally penalised in academia, but is a real problem for financial modelling.
- Having a vast multiplicity of algorithms tested by short periods of live trading simply ensures that there are always high performers whose performance is based on luck rather than a fundamentally accurate ML model, and which will fail in due course. Just as with human traders, it is impossible to tell luck from accuracy in the short term in live trading.
None of these are necessarily intractable problems. There are ML methods that are suitable to sparse time-series data. Overfitting of ML models is not inevitable, but requires great discipline to avoid; in the words of one anonymous data scientist, “You need to treat [financial] data like gold. The more you use it, the more you spend it.” The problem of dealing with the vast number of algorithms is not so simple, though – the parallel with measuring the performance of human traders is deep. In some ways, the only measure is to define a time in the future, and if the algorithm or trader is still flipping the coin heads-up at that time, then they are successful. How to apply this to select crowdsourced algorithms is unfortunately what scientists like to call an “open problem”.
This article was edited in partnership with Professor Jonathan Tapson. For more information about content partnerships, guest contributions, and exposure on Emerj.com, visit the Emerj Partnerships and Advertising page.
Header image credit: Fordham Law News – Fordham University



















{kind=link}
{kind=link}
{kind=link}