


Using Amazon.com makes it seem like eCommerce search just “works.” Type in the title of a book (“The Catcher in the Rye”), a general description of apparel (“red rain boots for kids”) or electronics (“green Playstation 3 Controller”), and you get what you were looking for.
It’s not as easy as it seems. In fact, eCommerce and online retail search often require huge volumes of manually labelled data.
To understand a string of words, a search system must infer which terms are related, and which terms relate to which inventory items in the online store. For online stores with tens of thousands (or in Amazon’s case, millions) of products, no pre-set series of rules can accommodate all the new searches of customers, or the flood of new and unique products being added daily.
I spoke with Charly Walther, VP of Product and Growth at Gengo.ai, to learn more about how crowdsourced labor is used to improve eCommerce search results – along with some tangible examples of when crowdsourcing might be used.
Why Crowdsourcing is Used in eCommerce Search Relevance
If we examine an eCommerce text string such as “red rain boots for kids”, we make sense of it intuitively. “Red” is a descriptor, a color. “Rain boots” is the item we’re looking for. “For kids” is an extra descriptive term specifying who the product is for, indicating that we’re looking for smaller sizes to fit a child’s feet.
None of that contextual insight about the text string “red rain boots for kids” is present in the actual string of text itself. Instead, AI systems must be trained to determine that “red rain” is not the object we’re looking for, and neither is “for kids.”
While some of this entity extraction and determination of terms, adjectives, etc, might be done by an “out of the box” natural language processing solution, the context around a certain domain or language generally must be added by human beings.
This is where crowdsourcing comes in. When terms need to be understood within a specific domain or context, and within a certain language, additional human judgement is often needed to make the data rich enough to train an effective, specific algorithm.
Walther emphasized that indeed context and language are often the critical reasons that clients work with Gengo.
“Companies expanding into ten different countries will either find ten different firms in those countries to handle data labelling – or they’ll work with Gengo to handle all ten countries.”
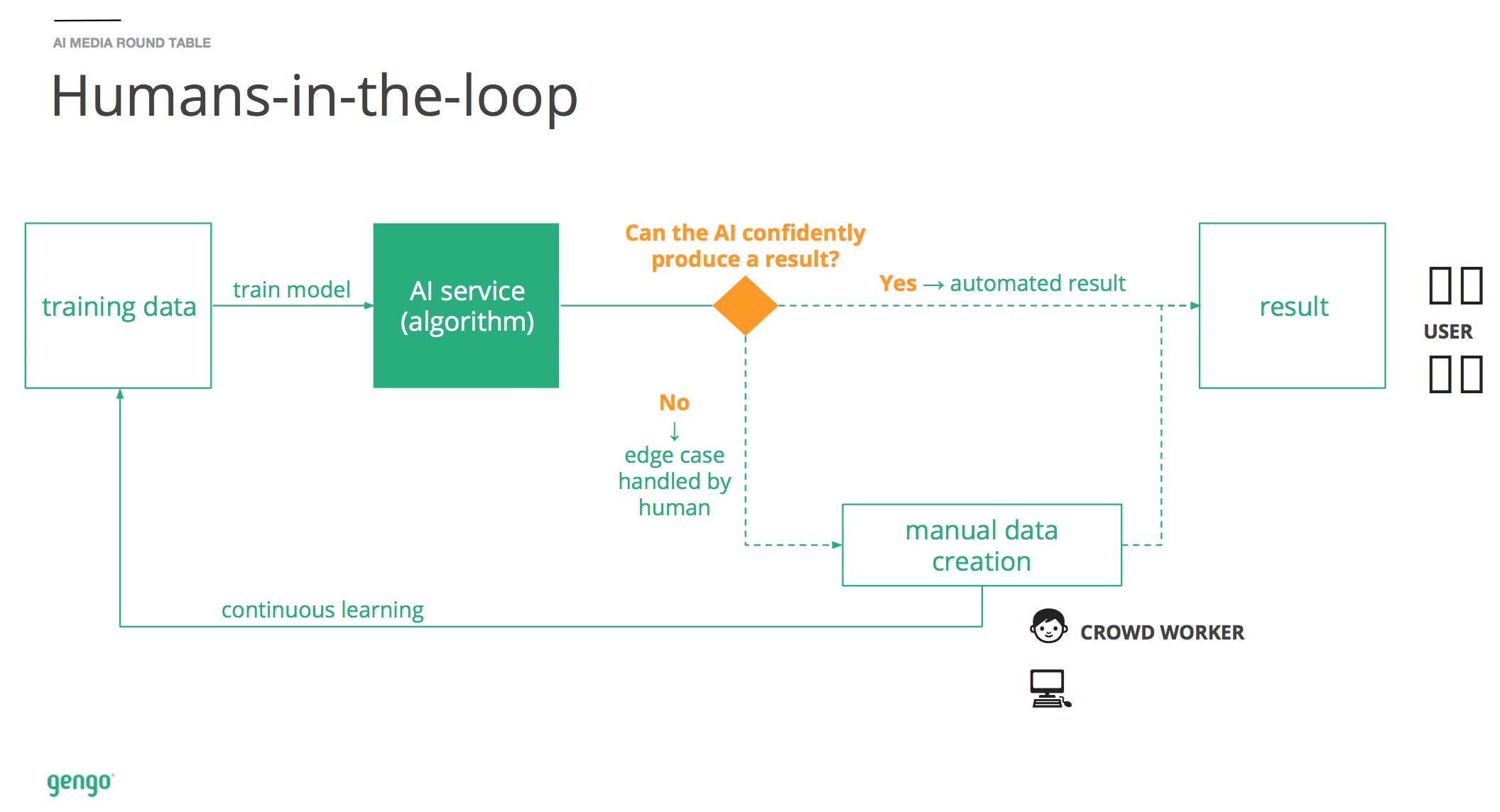
In the representative examples below, we’ll elaborate on a number of hypothetical use cases for crowdsourced data labelling for improving eCommerce search, exploring a bit more about how the process works, and when it might be relevant.
Example 1: eCommerce Language Challenges
Company: Online furniture retailer
Goal: Expand services and offerings into Europe
A UK-based company making an initial move into the German eCommerce market would need to make significant updates to existing website features before creating a German version of the site.
After translating the website’s content and product listings (a task that in itself is likely to require crowdsourced labor), the company would have to update their search algorithms to tie German words and strings of words into coherent search results for products.
This involves much more than simply replacing searches for “red aluminum chair” to the German translation “roter Aluminiumstuhl”. Unique phrases, terms, and grammatical rules have to be taken into account, and this robust task is often best accomplished by human beings with native fluency in the language, and some understanding and context of the subject matter (in this case, “furniture”).
Translations of products would have to happen first, and then various search results would have to be scored in terms of their relevance to actual German-speaking crowdsourced workers. This would likely involve a prompt to rate a set of possible search results for a specific search term, providing human interpretations of the relevance of various search terms (such as: “lawn furniture set”, “oak dining table”, etc).
This crowdsourced data work would involve a lot of upfront work, building a large corpus of human-labelled data to train a search algorithm which could then be used on the site.
In most cases, however, the need for training is ongoing. Waltham described how it usually works:
“The biggest amount of data is collected upfront to get the algorithm off the ground. After that, most clients will keep an ongoing stream of crowdsourced labelled data – at a lower volume – to keep the algorithm relevant with new products, and to handle edge-cases.”
Dr. Charles Martin is founder of Calculation Consulting, a machine learning consultancy firm based in Silicon Valley. Martin previously worked on search relevance AI projects at Demand Media and eBay. When it comes to search relevance, Martin emphasized the need for implicit feedback:
“Search relevance is about what people click on, it’s about implicit feedback. The way search algorithms work – and they’ve evolved over a long period of time. It’s the same with ads – you show people a lot of stuff, and they click. You do this over time and the algorithm learns from that click feedback.
In this case we’re not asking people to do a 5-star rating, we’re just seeing what they click on and how long they stay on the page, and that would be how we figure it out.”
Martin mentions that while training search algorithms is necessary, it’s important to design the experiment in a way that collects the right data – the kind of data that will lead to better search results. He states that businesspeople often develop ideas about what they think will inform a search model, but never run those ideas by the person developing the algorithm.
“People who are MBAs who design different kinds of data sets, and they bring them to the algorithm guy and he says there’s nothing to be done with that data.”
Martin states that there’s a lot of disconnects where people determine that they’re going to train a model on, but it’s not based on what will really work to train an algorithm to deliver the results the business needs.
Example 2: eCommerce Context Challenges
Company: Online jewelry store for women
Goal: Provide better search results and product recommendations, for higher cart value and value-per-visitor
While language is an important reason to use crowdsourced labor, it’s not the only reason. Context is key.
A natural language processing application trained to help summarize legal documents for lawyers is unlikely to be the best solution for summarizing events about football games, or biographies.
Similarly, a general search application – or apparel-related search application – is unlikely to apply perfectly (or maybe even well at all) to a set of jewelry-specific inventory.
In this case, the online jewelry store may rely on more than out-of-the-box tools like ElasticSearch, and they may train their own search algorithms with crowdsourced help. Because this hypothetical business sells mostly to women, they might seek to crowdsource women within their customer age range – and in particular – women with an interest in or taste for jewelry.
This is where context comes in. There is no linguistic rule stating that a search for “broaches” should in any way be related to “hair pins” – but it may be the case that the two searches are related, and women interested in one are often interested in the other. There is no linguistic rule stating that users searching “dichromatic glass” are almost always interested in necklaces and not earrings, but it may be discovered through crowdsourced input that necklaces are indeed what is intended by this kind of search.
These are hypothetical nuances, but they represent the kind of deeply contextual sense of preference, taste, and relevance that is often inherent in a specific eCommerce niche. These nuances often mean that custom-trained search algorithms (not out-of-the-box search offerings) are often the best way to satisfy users and maximize conversion rates for the business.
How the Crowdsourcing Process Works
Clients come up with rules of what, or how, to tag things, what / how to organize things, and then those directions are given to crowdsourced workers in order to provide the kind of data and labelling that’s needed.
In speaking with Martin, he mentioned that some clients have rather lengthy and detailed guidelines for their natural language-related projects, including:
- Which data is to be labelled (i.e. brand names, people’s names, etc)
- What is to be classified as an “entity,” and what is not
- How data is to be classified and sorted
Gengo’s job is the streamline those processes and executes on them in order to give the client the data they need to train their algorithms and solve their unique challenges.
About Gengo.ai
Gengo.ai offers high-quality, multilingual, crowdsourced data services for training machine learning models. The firm boasts tens of thousands of crowdsourced workers around the globe, servicing the likes of technology giants such as Expedia, Facebook, Amazon, and more.
This article was sponsored by Gengo.ai, and was written, edited and published in alignment with our transparent Emerj sponsored content guidelines. Learn more about reaching our AI-focused executive audience on our Emerj advertising page.
Header Image Credit: Mashable


















{kind=link}
{kind=link}
{kind=link}