


The banking sector has come a long way from the days of standing in lines to withdraw cash or report an issue. Today, customers just tap on a phone screen for most of a customer’s needs. According to a survey published last year by Oracle, 56% of customers believe their customer experience has improved the most in the last two years with new entrants like digital wallets and digital payments.
Technologies like artificial intelligence and machine learning sit at the back of these consumer-facing applications doing all the work for digital payments. Making sure there is no downtime, processing the true positive transactions without delays, and offering customers a recommendation engine that helps them invest better are the roots of enhancing customer experience.
In this article, we will explore three of the most prevalent real-world use cases for machine learning in banking. For each use case, we further discuss the business challenge said technology solves, the data being leveraged in the process, and the distinct benefit that machine learning applies to the processes therein.
The use cases we will explore include the following:
- Autonomizing reconciliation of accounting statements: Eliminating error and reducing human interventions with data-based, self-learning models.
- Hyper-personalization in customer experiences: Offering every customer a unique feed and offers based on his likings and needs.
- Detecting fraud and other deviant behavior: Training models to automatically detect and create an alert for deviating, sometimes criminal, behavior in transaction ledgers.
We will begin with machine learning’s wide application to fraud detection workflows.
Use Case #1: Autonomizing Reconciliation of Accounting Statements
Medium to small local and community banks operate at a scale where reconciling their accounting statement through human agents is a necessary part of the process.
However, for a company operating at a national or multinational scale, reconciling the accounts with too many humans and not enough automation tends to invite errors, particularly in reconciliation workflows. As cash flow grows, the process becomes time-consuming, increasing the possibility of errors exponentially.
Further, processing and checking invoices become cumbersome for a company operating across countries with different languages. Even a tiny mistake can create a delay and may also impact the business’s financials negatively.
Among AI capabilities currently available to banks – both among a wide array of vendors and, in some cases, potential beachheads for early AI adoption – machine learning is especially applicable in repetitive and error-prone workflows like reconciliation.
As we will show in the following vendor example, machine learning is a cross-industry example of an AI capability enabling systems to ingest data from various sources and match and reconcile it with internal sources. This engine can process millions of historical transactions, point out mismatches and suggest further steps.
Vendor example: SAP Technology
SAP Technology is a subsidiary of SAP SE, a German multinational software company that reported €21 billion in revenue last year. The company offers a platform for ‘intelligent intercompany reconciliation’ that comes with machine learning capabilities built-in.
The workflow of the platform based on company demo videos show a service that helps users match the items that remain unassigned after the rule-based matching.
For a reconciliation accountant, the new workflow and data inputs take the following form:
1. The user opens the reconciliation statement overview to check the reconciliation status:
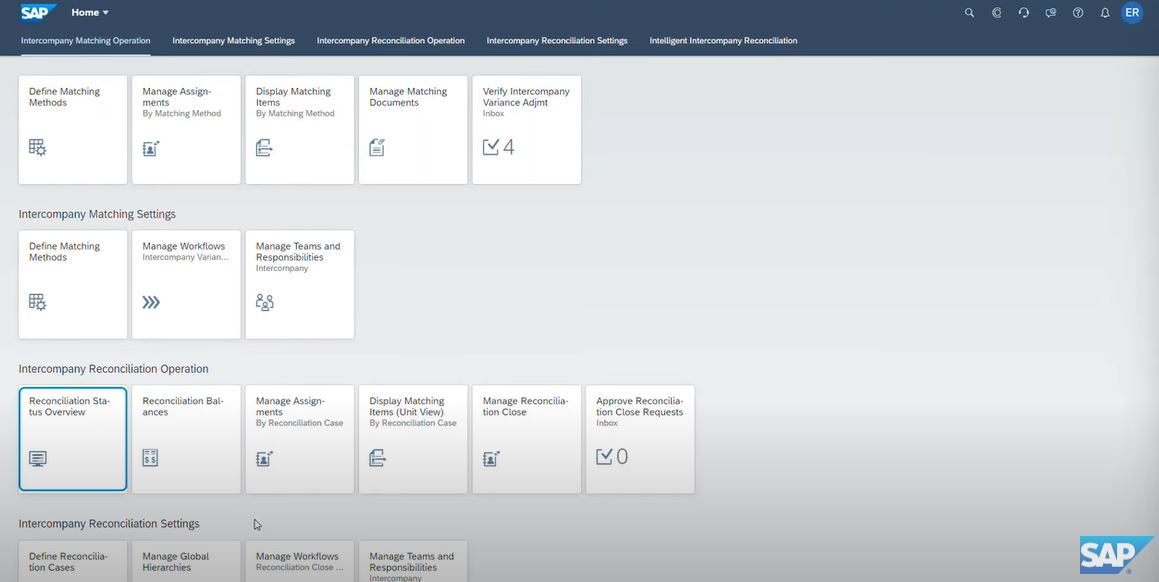
(Screenshot from SAP Technology Demo Video)
2. The user then navigates to balance details to check for differences.
3. The details screen shows (as in the figure below) a difference of USD $233.44:
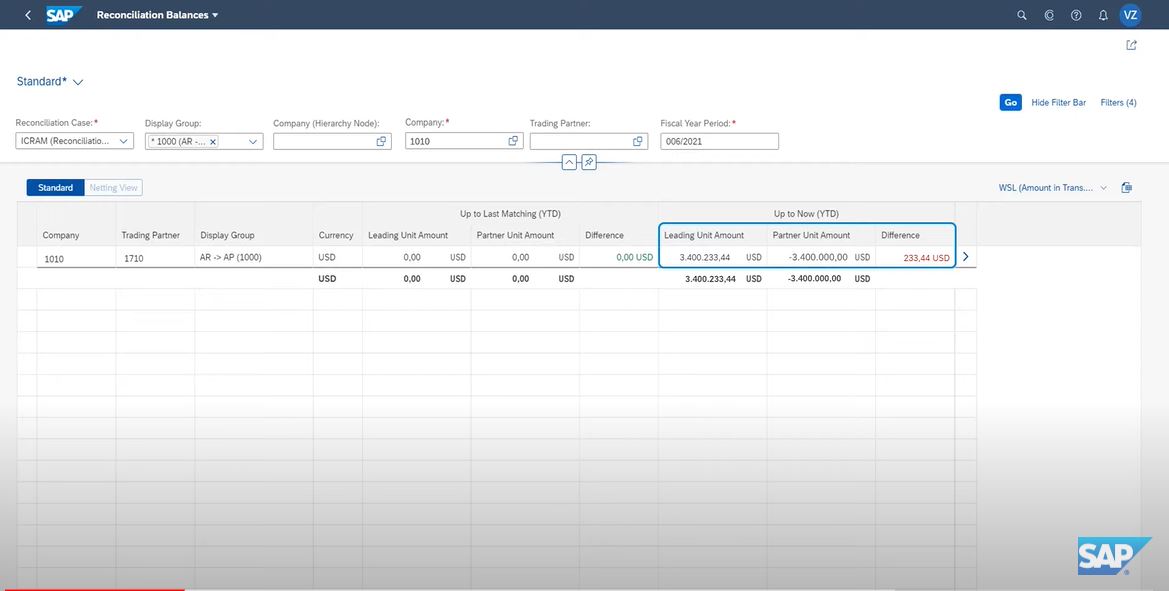
(Screenshot from SAP Technology Demo Video
4. The systems automatically match and reconcile the unmatched items by choosing to auto-match with functionality made possible through, SAP claims, machine learning.
5. After the matching job is launched, the system will perform a rule-based matching and send the remaining unassigned items to the AI service for further matching.
6. The two tables will initially be matched based on rules, and the remaining unassigned items will be sent to the ICR for machine learning reference.
7. The ICR uses SAP AI and runs on the SAP technology platform. It infers the results from the model, which is trained on company historic intercompany matched data.
After the inference is completed, the result is returned and displayed in the manage assignment app.
The workflow status will turn to approved on the manager’s approval, and the reconciliation status will be shown closed with no other differences in the financial statement.
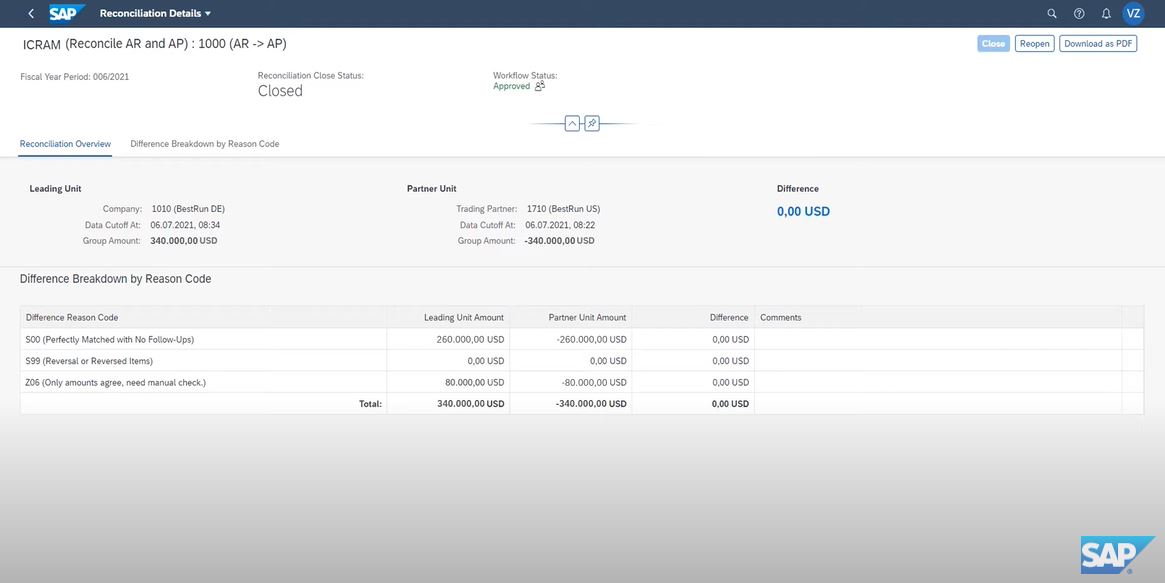
(Screenshot from SAP Technology Demo Video)
Below is a 5-minute video tutorial from SAP Technology, which demonstrates the process steps from checking intercompany reconciliation status, matching documents with ML inference, and completing variance adjustment workflow to closing period reconciliation.
In terms of business results, none were documented in the case study. However, from publicly available information, there have been multiple instances where the company reported they brought down the TAT from two months to two days using machine learning models to reconcile the financials.
Use Case #2: Hyper-personalisation in Customer Experiences
Gone are the days of mass advertising; now, customers desire ads that are suited to their needs and personal preferences. Enter an advertising era of hyper-personalization, made possible through machine learning and other applied AI technologies.
A survey in the fifth edition of Salesforce’s State of the Connected Customer report [pdf] found that 73% of respondents want companies to understand their unique needs and expectations. Hyper-personalization in the 21st century is nearly unthinkable without training models on customer behavior.
For banks, one of the significant use cases in hyper-personalizing customer experiences comes from the credit card department. The bank can provide unique and personalized offers to customers using their historical data, spending patterns, and location data.
Vendor example: Gathr
While speaking on a webinar, a Gathr Technical Product Manager Saurabh Dutta shared a use case for the credit card division, which ultimately resulted in benefiting the company with two million plus revenue.
The process adopted by the company was to first pull the data from the database to the data lake and build models on the data gathered:
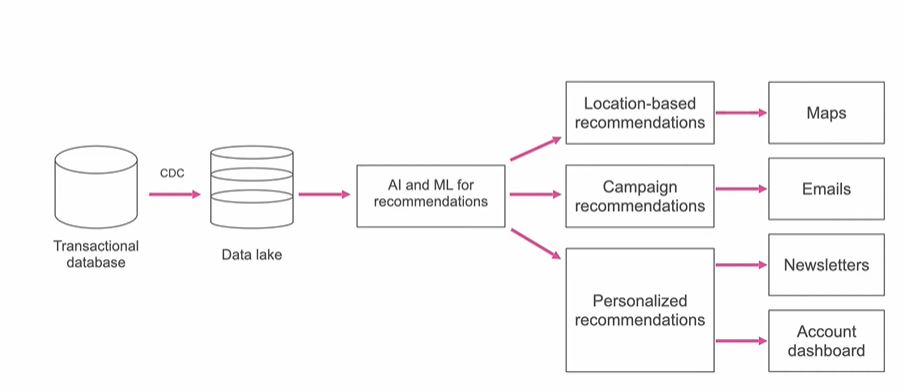
Screenshot from Gathr webinar. (Source: Gathr)
The workflow for the above process takes the following appearance in the platform dashboard:
1. On clicking the plus icon, the user gets to create a new CDC application. From here, he can choose a name and choose the template from which data is used:
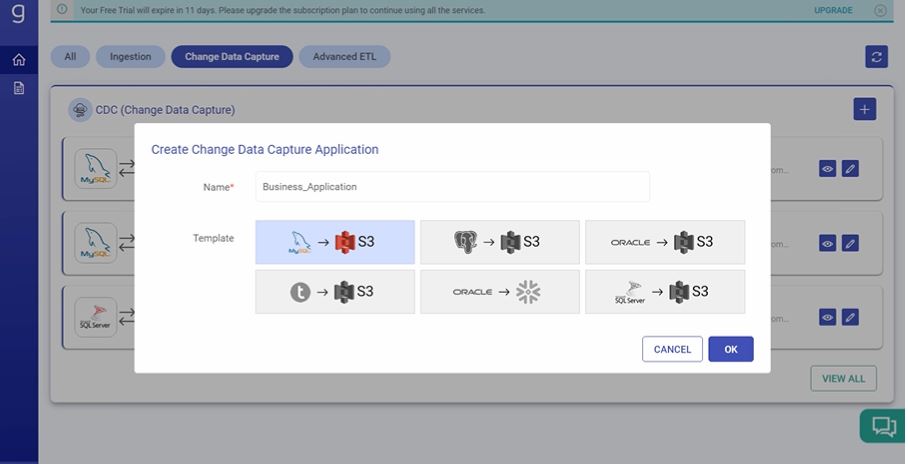
Screenshot from Gathr demo. (Source: Gathr)
2. The user then fills in details about database connection, method to capture data, Kafka connection and pluggable database on the source panel:
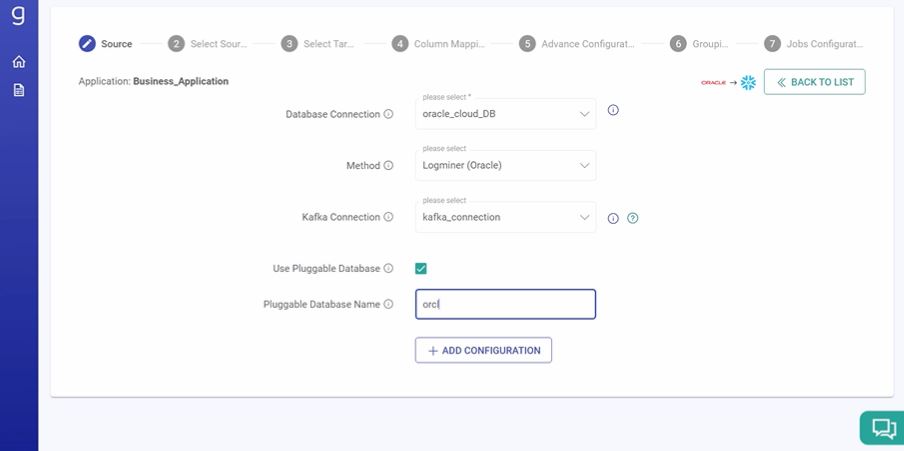
Screenshot from Gathr demo. (Source: Gathr)
3. Once the advanced configurations, table selection and column mapping are done, the data is transferred to the data lake.
4. Further, the user can build the recommendation models as per the business need.
Screenshot from Gathr demo. (Source: Gathr)
In the same webinar, Saurabh further mentioned that once Gathr “had customers’ credit card data in the data lake, we built a fine-tuned recommendation model. Over 500 features and parameters were considered to create the model to offer location-based, campaign, and personalized recommendations.”
The modeling algorithm used was gradient boosting. Once ready, it could produce real-time predictions and personalized recommendations.
According to Gathr promotional materials, the platform provided the following specific benefits:
- Providing personalized recommendations across four marketing channels in 14 markets,
- Processing 3.5 million recommendation requests per day
- Increase the wallet share for credit card
- 2 million plus increase in annual revenue
Use Case #3: Fraud Detection
Banks process millions of daily transactions across geographies, making the ability of humans to sit and monitor every transaction to detect fraud a physical impossibility. That is why banks set a mark on a certain amount to alert the systems about fraud so that thorough investigations can be done.
Imagine a team of analysts and investigators researching why someone made a high-value transaction. The research could take hours, if not days, to come to a decision, and it is a well-known fact that the longer it takes to process the customer’s buying journey, the lesser the buyer will buy from your company.
Screenshot from Amazon Web Services (Source: Amazon)
Thus machine learning comes as a super-fast option to investigate and process transactions in near-real time. But machine learning models don’t become operational overnight.
They consider historical data and usually require eight to ten months of data collection and early adoption strategizing from an entire organization before it can properly start processing data as an ROI.
Vice President and Global BFSI Domain Head at Happiest Minds, Subhasis Bandyopadhyay tells Emerj researchers that machine learning capabilities are particularly well suited to the nuanced workflows of fraud detection in banking, which can equally be based on seasonality:
“For machine learning to work on fraud detection, you have to train it in a way that considers external factors like the location of the transaction, holidays, socioeconomic conditions, or even the political scenario. In my experience, banks can reduce 40 – 50% using machine learning with fraud detection.”
– Vice President – Global BFSI Domain Head, Happiest Minds, Subhasis Bandyopadhyay
Vendor example: Amazon Web Services
Amazon’s Web Services offers small and medium-sized businesses an all-purpose fraud detector tool that the tech behemoth claims is powered with machine learning.
Much of the promotional materials for the service describe a credible background for noncoding enterprise professionals on the nature of machine learning and general applicability of the technology to fraud detection workflows.
Traditional rule-based fraud detection systems are fundamentally based on rules made by human experts – usually basing the process on an organizational protocol, regulatory compliance procedure or more merely according to the applicable legal statute.
In these cases, experts create rules to determine if the system should flag a transaction as indicative of fraudulent behavior. Rules-based systems writ large can have many shortcomings. For one, rules are fundamentally static and need constant updating to conform to dynamic times.
Instead of handcrafting rules, businesses can use machine learning to learn and adapt the behavior of fraudsters. Machine learning helps us create models which are self-improving and maintainable. Importantly they can scale as the business grows.
AWS divides its development of machine learning tools strictly into two categories:
- Supervised learning: When we have access to labeled data
- Unsupervised learning: When we only have access to raw data.
Promotional media on the functions of AWS depict the difference between the two, as demonstrated in the following screenshots:
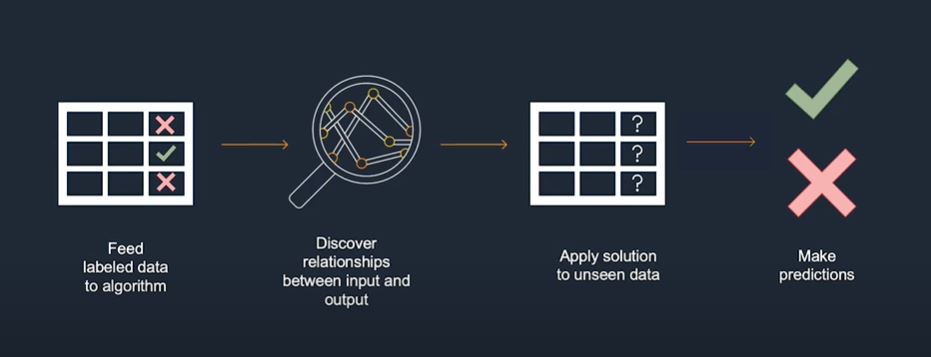
A slide on supervised machine learning learning
taken in a screenshot from AWS demo video. (Source: Amazon)
For supervised learning, the business can train the model to discover relationships between inputs like transaction time, amount, country and IP address. Once we train the model on the existing data set, businesses can deploy it to identify fraud in live data.
A slide on unsupervised machine learning learning
taken in a screenshot from AWS demo video. (Source: Amazon)
For unsupervised learning, AWS uses unsupervised learning algorithms that are able to discover structure in data and allow us to potentially fraudulent transactions.
AWS uses an Amazon program called SageMaker to “Build, train, train both the models for “any use case with fully managed infrastructure, tools, and workflows.”
In other words, when new data arrives, the business can use these models to get an estimate of their anomaly score.
To create a model on AWS, the user has to:
1. Define the model details in Fraud Detector.
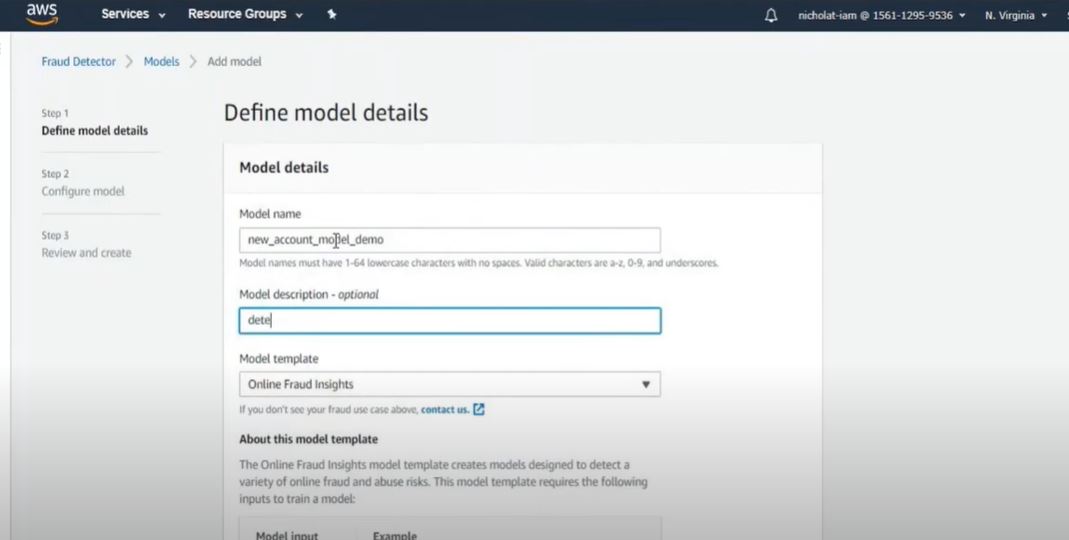
Screenshot from AWS demo video. (Source: Amazon)
2. The user will upload the training data set to the service for the model to work on.
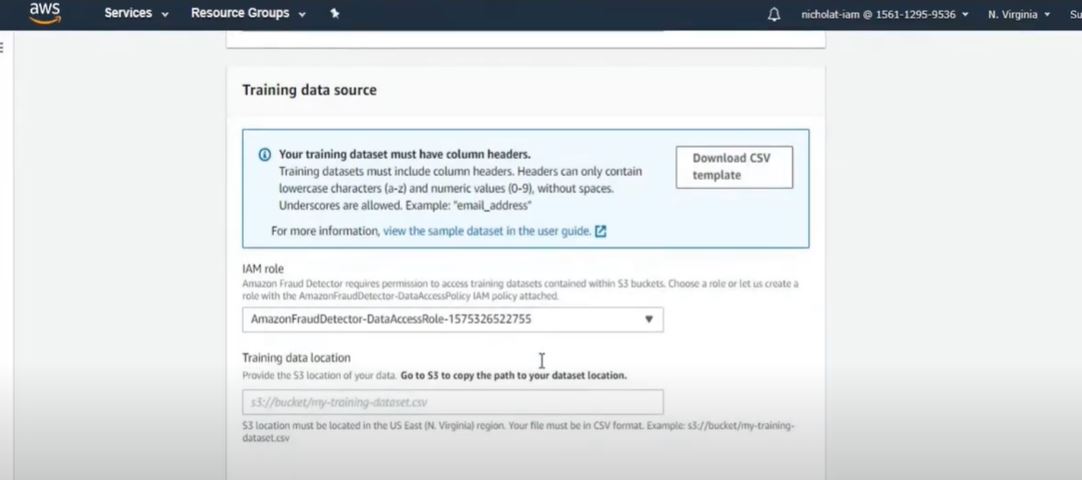
Screenshot from AWS demo video. (Source: Amazon)
3. The service will automatically pull up the columns from the training data set. Here, the user will have to define what values should be recognized as fraud or legitimate.
4. Once the model is created, AWS will show the model performance score and AUC:
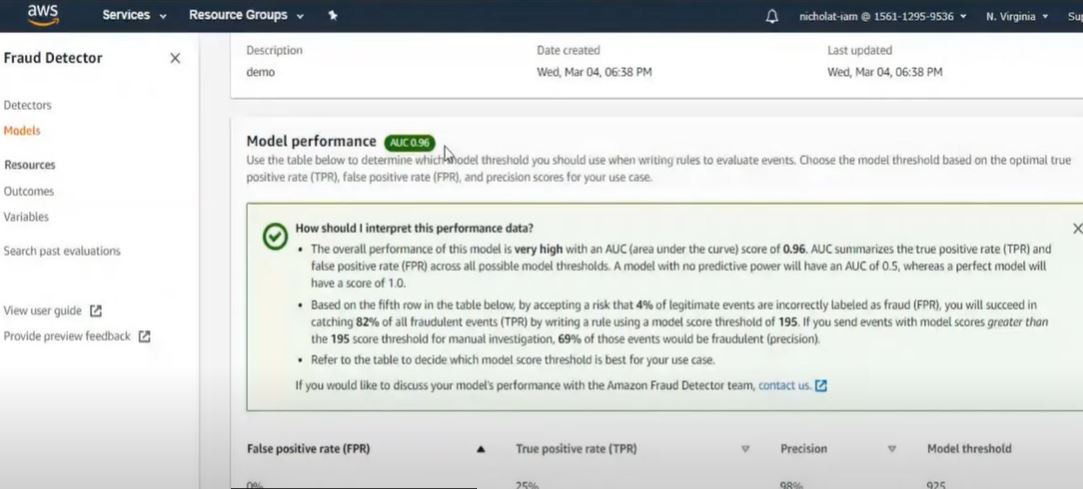
Screenshot from AWS demo video. (Source: Amazon)
5. After deploying the first version of the model, the user can run a test to verify the model’s performance.
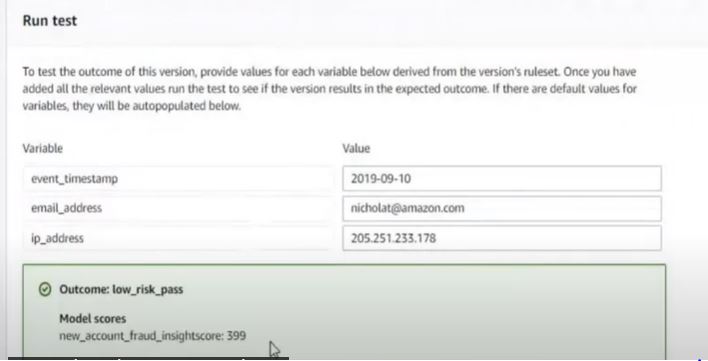
Screenshot from AWS demo video. (Source: Amazon)
From this point, as per the business needs, the user can edit or publish their findings for real-time detection of fraudulent transactions.
The video below serves as a deep-dive into Amazon Fraud Detector, including its dashboard and general platform functionality. Skip to 14:25 for the demo session, which runs approximately two and half minutes in length:
















{kind=link}
{kind=link}
{kind=link}